[Tech] UTF:Unicode 的實現方式
有了 Unicode 這本字典之後,我們很容易的就可以將字符和對應的碼位關聯在一起。
舉例來說,「你」這個字的碼位為 U+4F60,也就是被編列在 0x4F60 的格子,其中 0x 表示十六進位,轉成十進位的話是第 20320 個格子。
那麼,接下來的問題是,電腦要怎麼儲存?因為電腦「依舊」只認得 0 與 1 啊。
在前面提到的 ASCII 裡面,每個字符都固定為 1 個 Byte,也就是 8 個 bit,共有 256 種組合。換句話說,只要我們想要放入的字符數量少於 256 個,就可以透過 1 個 Byte 來表示形成一對一的對應關係。
但是在 Unicode 裡,可是規劃了 1,114,112 個格子呀!我們要怎麼把對應的碼位「轉變成」電腦看得懂的形式呢?於是,Unicode 定義了不同的 UTF 格式(Unicode Transformation Format),用來將碼位轉為二進位形式,其中包含 UTF-8、UTF-16 和 UTF-32 三種實現方法。
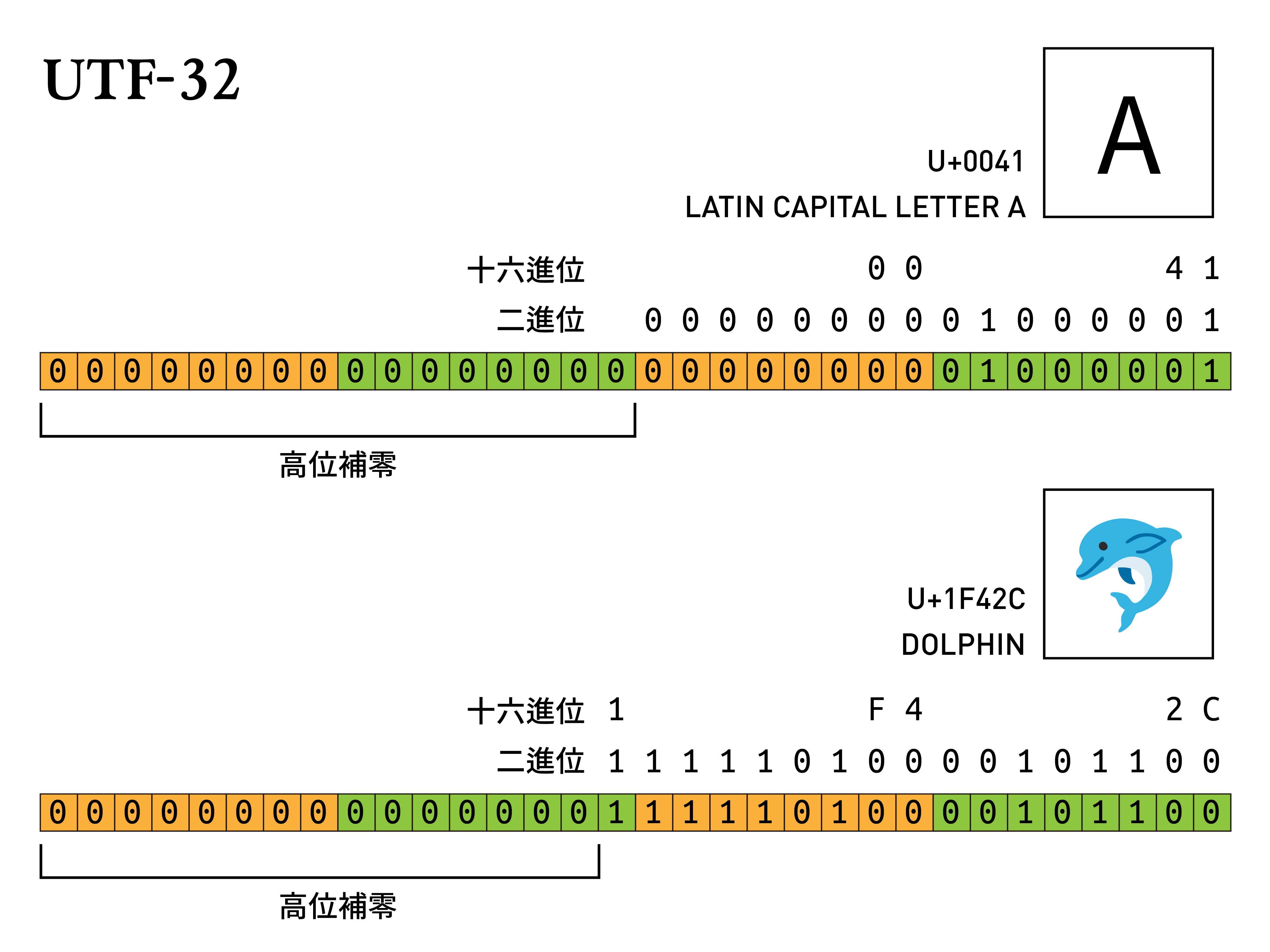
UTF-32
UTF-32 顧名思義,就是將每個字都用 4 個 Byte,總共 32 個 bit 來進行碼位的編碼。考慮到每個 bit 都可以是 0 或 1,因此至多可以產生 2^32 = 4,294,967,296 個組合,這個數量已經遠遠超出 Unicode 的所有格子,因此,我們只要很簡單的把 Unicode 的碼位轉成二進位後,然後把前面補零即可。
以海豚這個 Emoji 🐬 為例,其在 Unicode 的編碼為 U+1F42C,轉成二進位後是 0001 1111 0100 0010 1100,往前補齊零就是 UTF-32 的格式。
| Byte | Byte | Byte | Byte | |
|---|---|---|---|---|
| 十六進位 | 1 | F4 | 2C | |
| 二進位 | 0001 | 1111 0100 | 0010 1100 | |
| UTF-32 | 0000 0000 | 0000 0001 | 1111 0100 | 0010 1100 |
UTF-16
不過,如果你仔細觀察,會發現 UTF-32 的前 15 個 bit(第一個 Byte 全部、以及第二個 Byte 的前七個 bit)始終都為零,畢竟 Unicode 的碼位數目用不到那麼多嘛,所以用 UTF-32 格式來儲存一個字符,其實是件相對沒效率的事情。
於是,Unicode 另外訂定了使用 16 個 bit,也就是 2 個 Byte 的 UTF-16 格式。
但是如此一來,便只剩下 2^16 = 65,536 個組合了,對於第 0 基本平面(BMP)的字符來說,這個數目剛剛好,但若要顯示第 1 到第 16 輔助平面的字符就完全不夠用了!
該怎麼辦?因此 UTF-16 用了相對動態的方式來儲存字符——如果該字符在 BMP 上,就用 2 個 Byte 來紀錄碼位;但如果該字符在輔助平面上,則和 UTF-32 一樣,使用 4 個 Byte 來儲存。
在 BMP 上,Unicode 預留了 U+D800 到 U+DFFF 為代理對(surrogate pair),其中 U+D800 到 U+DBFF 為高位代理區(high surrogates)、 U+DC00 到 U+DFFF 為低位代理區(low surrogates),兩區各有 1024 個碼位,這兩區的碼位不做任何的字符分配。
需要「代理」的時候,只要將兩者各取一碼,則能產生 1024*1024 = 1,048,576 種組合——剛好對應第 1 到第 16 輔助平面上的 1,048,576 個字符!
以剛剛的海豚 🐬 為例,其碼位以十六進位表示為 0x1F42C:
- 我們先把它減去
0x10000,得到0x0F42C - 將
0x0F42C轉成二進位後是0000 1111 0100 0010 1100 - 接著把這串二進位 對半切,拆成高位與低位的兩組,即
0000 1111 01與00 0010 1100 - 再將兩組二進位轉成十六進位,分別是
0x3D與0x2C。 - 前者(高位)加上
0xD800,得到0xD83D - 後者(低位)加上
0xDC00,得到0xDC2C - 因此,
0x1F42C便可以用D8 3D DC 2C來表示。
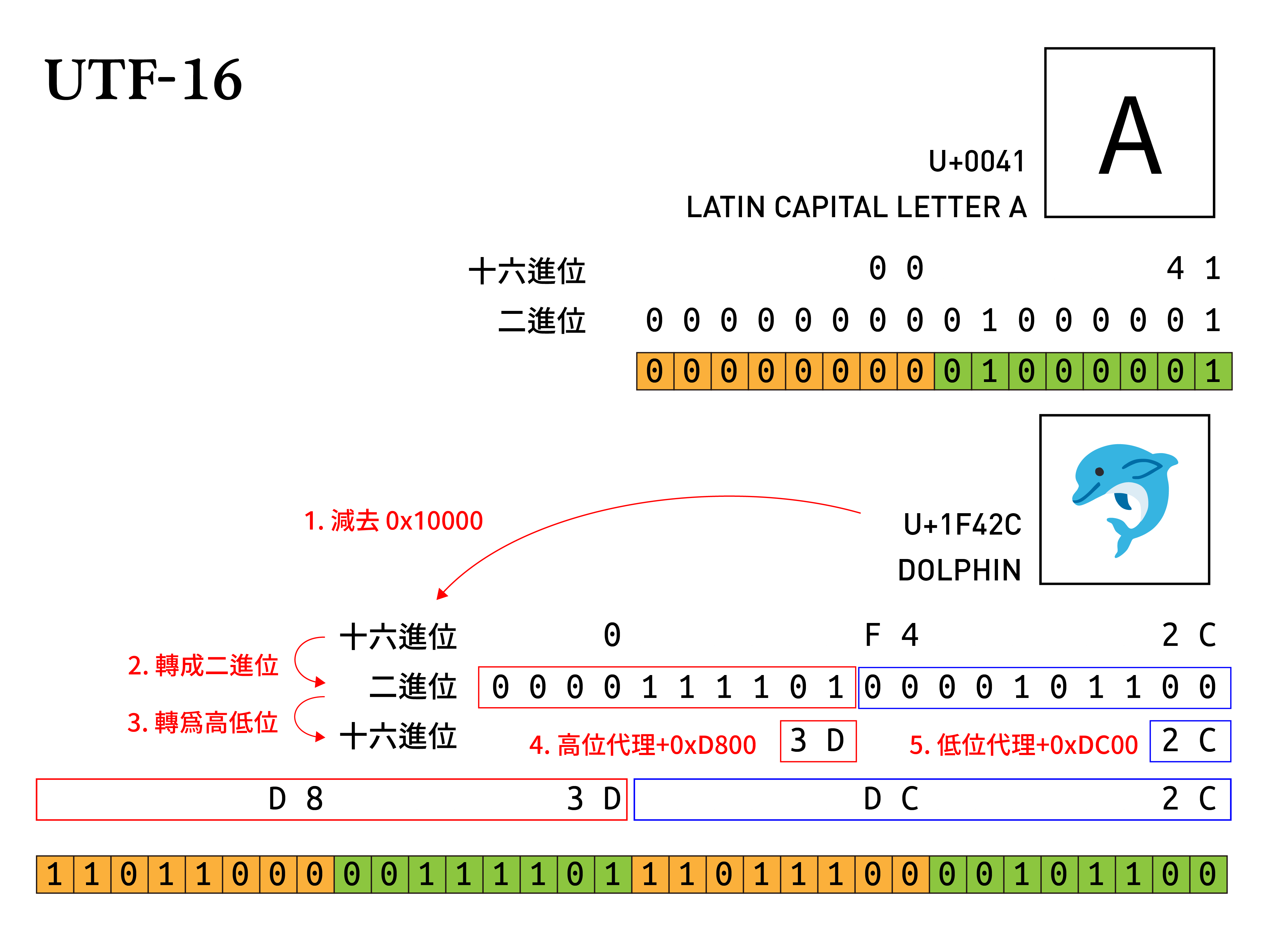
而對於程式處理來說,平常都預設使用兩個兩個 Byte 為一組去讀取字符,但只要掃到高位代理區的碼位,就可以知道接下來一定是低位代理區的碼位,且該「字」是由四個 Byte 來儲存的。
如此一來,我們就可以用一種相對有彈性的方法來處理 Unicode 了。
UTF-8
儘管 UTF-16 允許使用至多四個 Byte——常用的 BMP 只要兩個 Byte 就足夠——來紀錄 Unicode,但我們還能不能用更少的 Byte?舉例來說,英文、數字以及大部分的符號都放前 128 個位置,這裡其實只需要用 8 個 bit、一個 Byte 來表示就足夠了!
UTF-8 讓我們得以依循古法,將 ASCII(0x00 - 0x7F)的字符用 1 個 Byte 來表示,0x80 - 0x7FF 使用 2 個 Byte,0x800 - 0xFFFF 用 3 個 Byte,輔助平面的 0x10000 - 0x10FFFF 則用 4 個 Byte 來儲存。計算方法也相對簡單,只要將碼位轉成二進位再按表填入即可,剩餘的高位補零:
| 碼位 | Byte | Byte | Byte | Byte |
|---|---|---|---|---|
0x00 - 0x7F |
0xxxxxxx | |||
0x80 - 0x7FF |
110xxxxx | 10xxxxxx | ||
0x800 - 0xFFFF |
1110xxxx | 10xxxxxx | 10xxxxxx | |
0x10000 - 0x10FFFF |
11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
一樣再舉海豚 🐬 為例, 0x1F42C 轉成 00011111010000101100,由右至左填入後可得
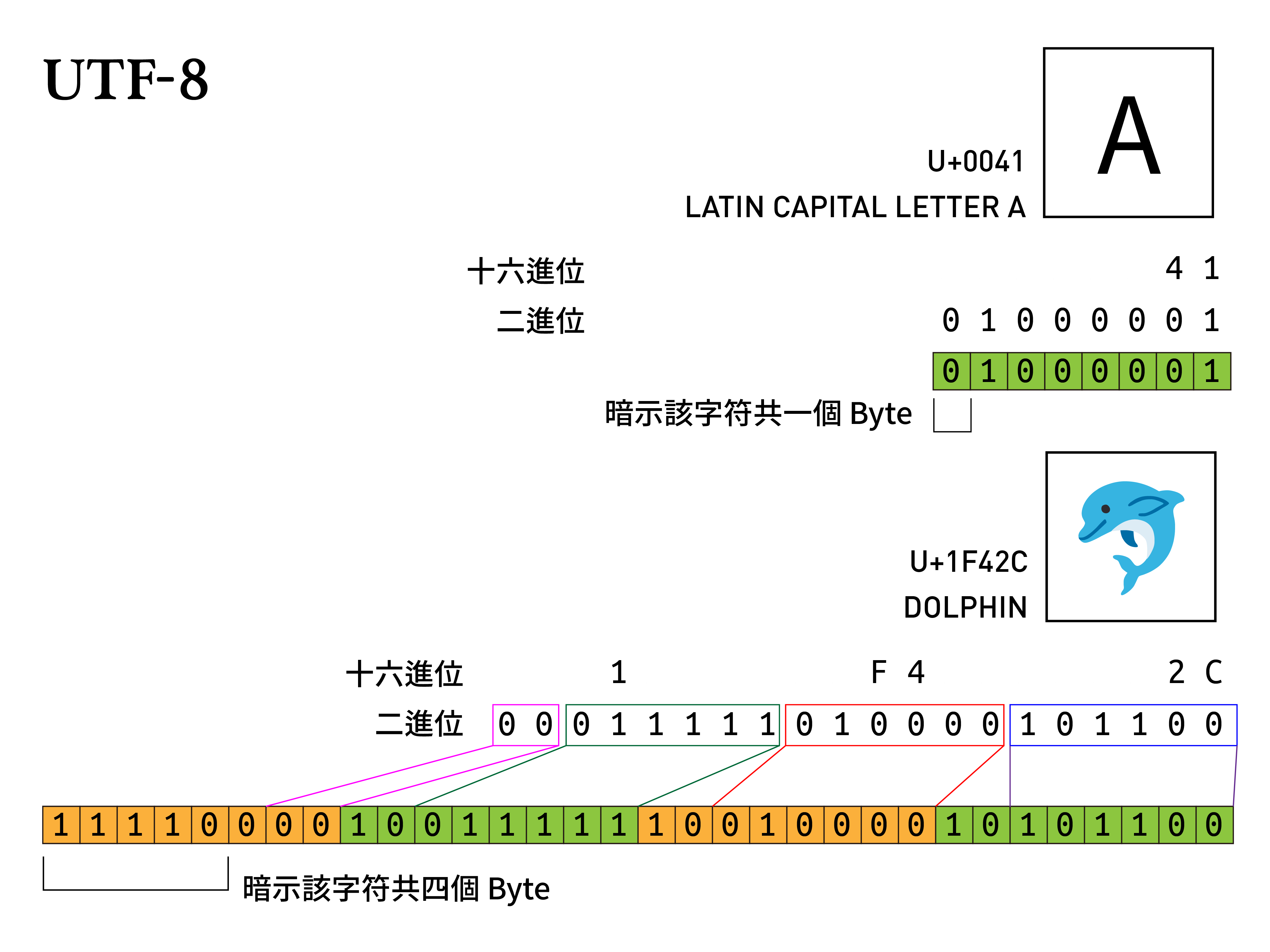
還記得我們前面有提到,ASCII 會成功的關鍵之一,便是因為其保留最高位的 bit 為 0,讓後來擴充字集都可以很簡單的「迴避」基本區(只要不用 0 開頭就好)。這點在 UTF-8 編碼規則上尤其重要,程式只要看到非 1 開頭的 Byte,就可以知道這個「字」僅佔了 1 個 Byte;而剩餘以 1 開頭的字符,只要知道遇到第一個 0 之前有有幾個 1 ,就可以知道該字的長度——以 11110 為開頭的話,便可以知道該字符佔了 4 個 Byte。
對於一份僅有英數的文件和檔案來說,使用 UTF-8 編碼存擋,僅需要 UTF-32 的四分之一、UTF-16 的一半大小。
UTF-8 已經是目前多數網頁和文件的事實(de facto)編碼標準。
遺留的技術債
UTF-8 相較於其他兩種編碼,雖然其字符長度是可變的(有可能 1 Byte 也有可能 3 Byte),但也相對地節省空間。
考量到平常會用到的字都在 BMP 上,不太有需要使用到輔助平面,因此 MySQL 預設只使用了至多 3 個 Byte 來儲存字符,這個規格叫做 utf8mb3,其中的 mb 表示 most byte,也就是至多的 Byte 數量。
但在 Emoji 出現之後,utf8mb3 就無法正確的儲存這些小可愛了,所以後來 MySQL 才新增了可以儲存四位 Byte 的 utf8mb4 格式。如果你的 Wordpress 無法儲存 Emoji 的話,通常就是因為使用了舊的 utf8mb3 格式,趕快把他調成 utf8mb4 吧。
| 每個字使用的 Byte | 優點 | 缺點 | |
|---|---|---|---|
| ASCII | 1 Byte | 最簡單。如果只要顯示英文、數字與符號已經足夠 | 超出範圍的字符將無法編碼 |
| UTF-32 | 4 Byte | 無需轉換,可以與 Unicode 碼位直接對應。字符固定為四個 Byte,程式處理方便 | 所佔空間大,會有大量的 bit 為 0 |
| UTF-16 | BMP 上的字符為 2 Byte,輔助平面的字符為 4 Byte | 常用的字符都在 BMP 上,所以幾乎都能用 2 個 Byte 來表示 | 但 Emoji 在輔助平面上… |
| UTF-8 | 1~4 Byte | 靈活,可以向下兼容 ASCII,最省空間 | 每個字符的 Byte 長度不一,程式要額外考慮「斷字」的切割 |
本文同步刊於 iThome。詳見DAY 06 | Unicode 的實現:UTF。