[Tech] Unicode 收錄的漢字狀況
收錄在 Unicode 裡面的「漢字」被稱作「中日韓統一表意文字」(CJK Unified Ideographs,偶爾會被稱作 CJKV,V 表示越南),相較於其他有明確定義的文字——例如英文小寫的 a 在 Unicode 的碼位是 U+0061,對應的名稱為 LATIN SMALL LETTER A ——CJK 的名稱都僅僅是 <CJK Ideograph>,因此,詳細的字符樣貌必須要回去參考 Unicode 的本本(可以點下面藍字的超連結)。
現況
目前(Unicode 15.1),Unicode 共收錄了 97,058 個漢字,包含(註:碼位為區域範圍,但不是所有的碼為都有分配,有些空著作為保留):
- CJK 基本區(BMP):
U+4E00-U+9FFF,共 20,902 字。 - CJK 兼容區(BMP):
U+F900-U+FAFF,共 472 字。 - CJK 擴充 A 區(BMP):
U+3400-U+4DBF,共 6,592 字。- 有趣的是,擴充 A 區的位置,居然比基本區還要前面!原因我們之後會談談。
- CJK 擴充 B 區(第二平面):
U+20000-U+2A6DF,共 42,720 字。- 這一區有很多漢字長得非常…微妙…尤其是甲骨文隸定字
- CJK 擴充 C 區(第二平面):
U+2A700-U+2B73F,共 4,154 字。 - CJK 擴充 D 區(第二平面):
U+2B740-U+2B81F,共 222 字。 - CJK 擴充 E 區(第二平面):
U+2B820-U+2CEAF,共 5,762 字。 - CJK 擴充 F 區(第二平面):
U+2CEB0-U+2EBEF,共 7,473 字。 - CJK 擴充 G 區(第三平面):
U+30000-U+3134F,共 4,939 字。 - CJK 擴充 H 區(第三平面):
U+31350-U+323AF,共 4,192 字。 - CJK 擴充 I 區(第二平面):
U+2EBF0-U+2EE5F,共 622 字。
當然,要把九萬多個字都造出來堪稱天方夜譚,即便是 Adobe 和 Google 聯手開發的思源系列(Noto),也只囊括了 BMP 與部分擴充區的字符。
對於日常生活中的使用,製作 7000 餘字已經(還是很多啦)相當足夠,例如 justfont 的「jf 7000 當務字集」便是一個相對可行的造字目標。
原則
還記得前天提到的 Unicode 收錄原則之一:Unification 原則,旨在統一不同語言中同一書寫系統中的相同字元。
舉例來說,英文字母雖然和德文字母的順序不太一樣(後者多了 Ä、Ö、Ü、ß 四個字母),但他們本質上都是拉丁字母,所以不會重複收錄。
反之,只要是不同來源的字母,即使長得有多像,甚至是看起來一模一樣,都應該被分開來收錄。因此拉丁字母的 T (U+0054) 、希臘字母的 Τ (U+03A4)、西里爾字母的 Т (U+0422) 理所當然的被分配到了不同的碼位。而英文的分號 ; (U+003B) 雖然和希臘文的問號 ; (U+037E) 長得一模一樣,也會被分別收錄。
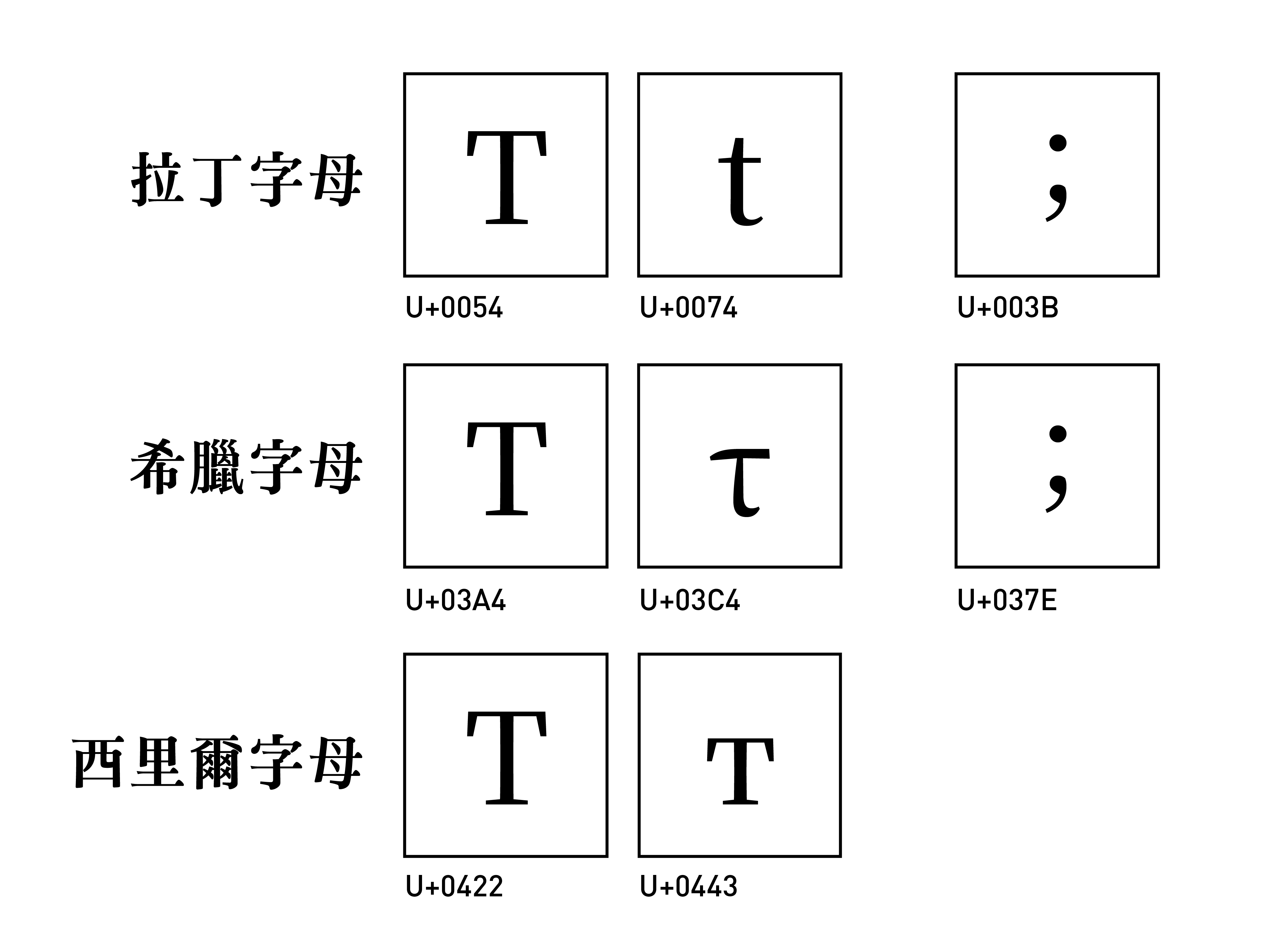
這樣做的好處之一在於大小寫的轉換,上面的三個 T、Τ、Т 的小寫分別對應 t (U+0074)、τ (U+03C4) 與 т (U+0442),我們就可以很簡單的透過索引值的加減來轉換。
倘若按照這個邏輯——「字集分離收錄規則」(Source Separation Rule: If two ideographs are distinct in a primary source standard, then they are not unified)——去收錄東亞文化圈的漢字,以 戶 字為例,在不同的官方標準中,第一筆有不同的寫法:韓國的傳統字形與臺灣教育部標準為撇筆,被收錄到 戶(U+6236);香港教育參考字形與中國規範則為一點,被收錄到 户(U+6237);而日本標準則為橫筆,被收錄到 戸(U+6238)。
此外,以 劍 這個字為例,當初日本就提交了六種寫法,包含戰前的舊字體以及戰後的新字體,收錄到了六個碼位:剣 (U+5263)、劍 (U+528D)、剱 (U+5271)、劒 (U+5292)、劔 (U+5294)、釼 (U+91FC)。
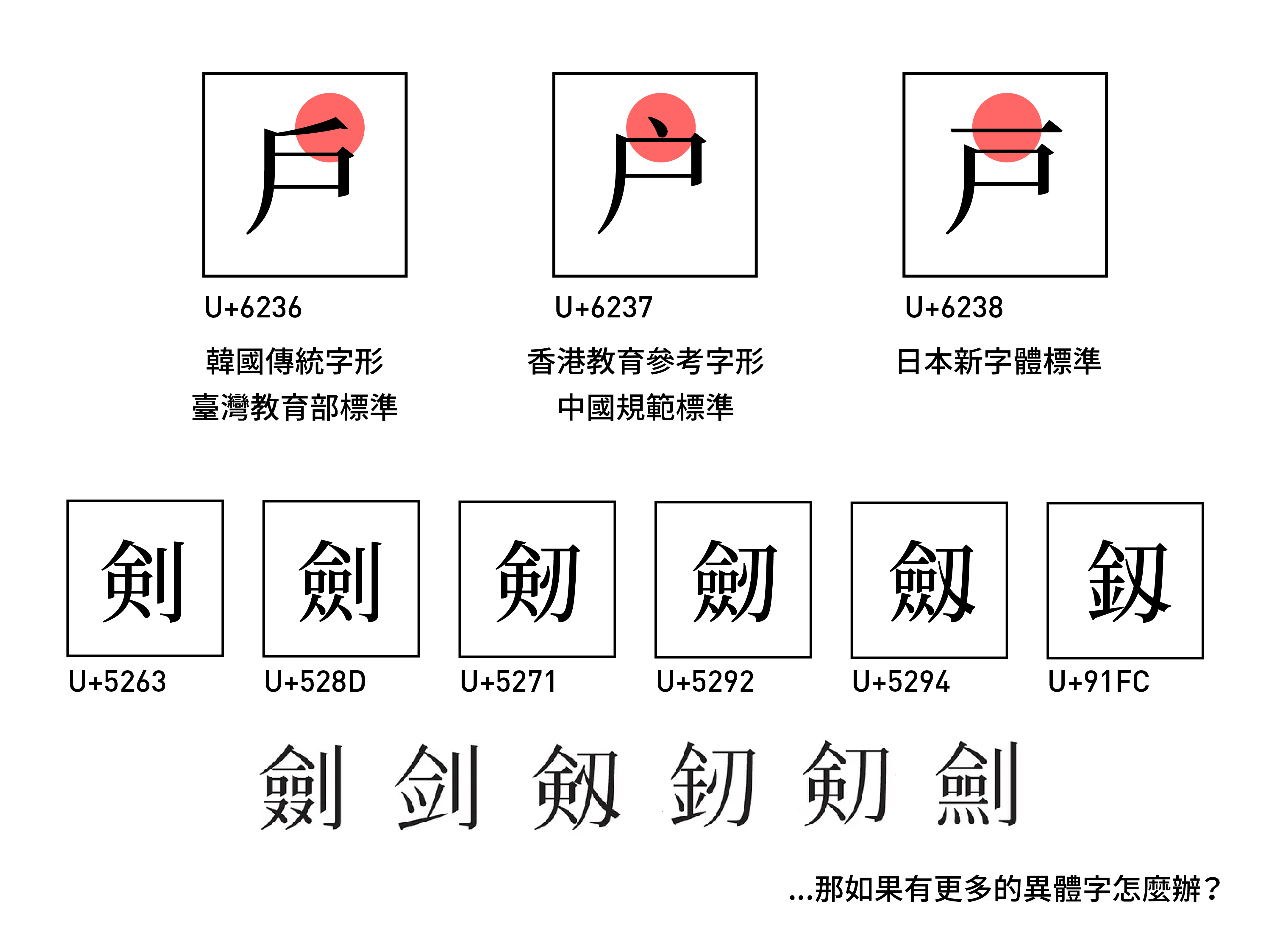
不過,拉丁字母、希臘字母、西里爾字母雖然起源於腓尼基字母,在分家後都獨立演化了數百年。但漢字——明明就是同一個字、意思也都接近、歷史起源也都一致,只是近代官方的標準不同而已,就要被拆成多個碼位分開儲存?
如果有其他的字跟 劍 一樣有極多的異體字,是不是就必須佔用更多的碼位?
即使 Unicode 還有很多空位,但如果特別去規定每個「漢字」該長怎麼樣子,像是第一筆應該要是撇、點、還是橫,似乎又和 Unicode 的 Characters, not glyphs 的抽象概念有所衝突,跟 Unify / 統一 實在相差極遠。
因此,後來的 Unicode 在 CJK 一事上放棄了字集分離收錄規則,額外訂定出表意文字認同原則(Han Unification Rule),透過「只針對字符本身,而不針對字長怎樣」的邏輯,就 應該 可以把上面的 戶、户、戸 合併成一個碼位處理,改由字型來區分字形。
舉例來說,一點一折的 ⻌(中國與日本的標準)、兩點一折的 ⻍(香港標準,臺灣、韓國與日本舊字體)、一點兩折的 ⻎(臺灣標準)被整合在一起,我們不需要再為了 近 分開編碼;而三點向內的 爫(中國大陸、港臺新字形)與三點向外的 ⺥(舊字形)也被合併,彩 字的造型將由字型檔案決定就好。

漢字問題,就此解決!
衝突與標準化
…才怪!
如果我們再想想,一開始的原則說只要提交來源不同,就盡可能地分開收錄;後來又說只要歷史同源,就要盡可能的統一——這兩種原則根本就是衝突的!因此,漢字便在這兩個衝突原則裡被收錄到了 Unicode 裡面,遺留了大量上古時期的技術債。
舉例來説,根據 Unicode 的 Stability 原則,已經被分配的碼位無法變動,因此上面提到的 戶、户、戸 碼位依舊,但像 房 這個字就被統一到一個碼位(U+623F)。青(U+9752)和 靑(U+9751)、淸(U+6DF8)和 清(U+6E05) 被分成兩個碼位收錄,但 請(U+8ACB)跟 情(U+60C5) 卻被合併在一起了!
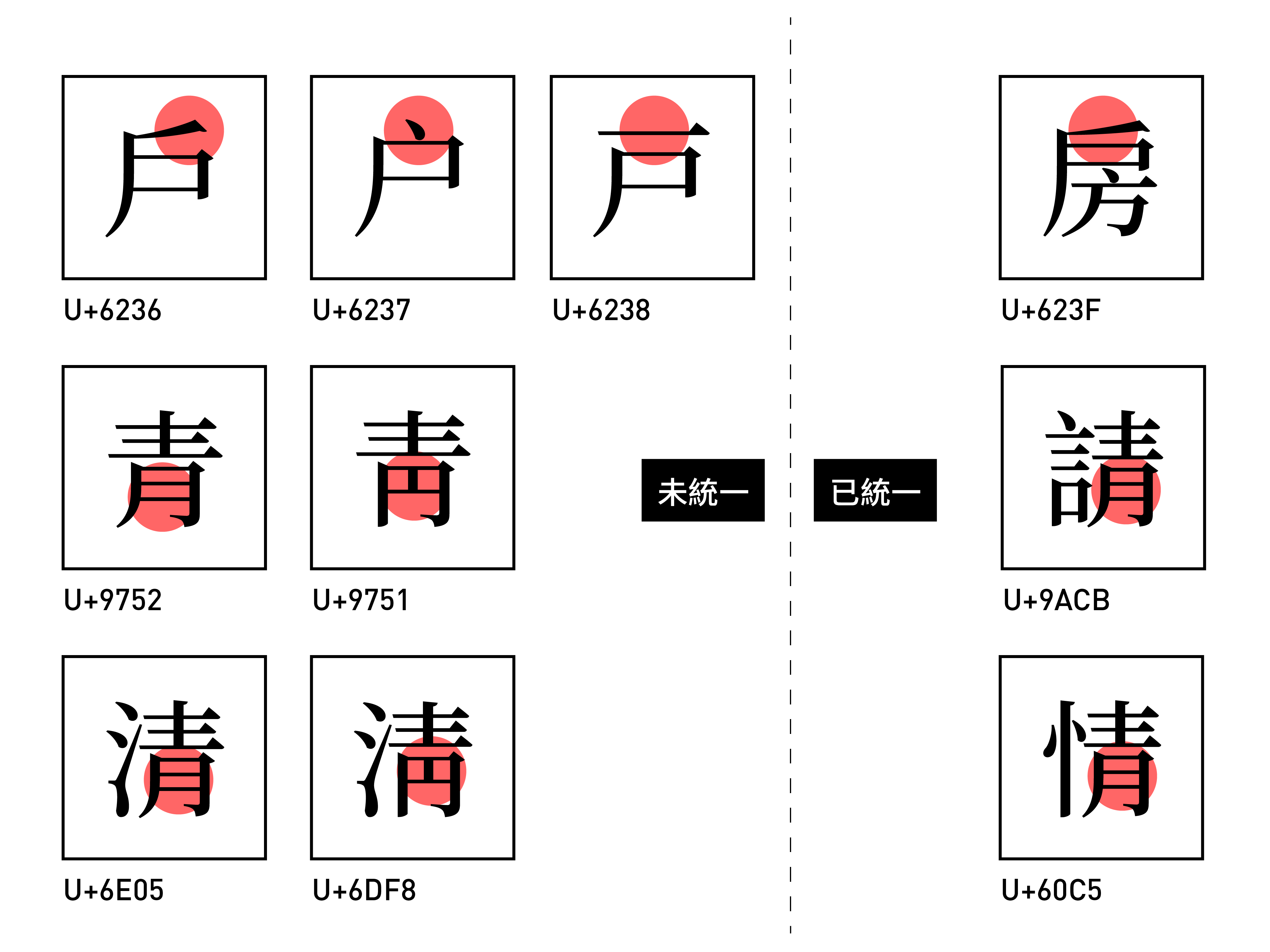
這類「未統一漢字」仍有近三百個。實際應用上,如果有模糊搜索、比對字符的必要,應該透過額外的標準化方式(normalization)將其統一,否則如果內文使用的是 户,但使用者搜索了 戶,就會找不到結果。
而在造字的時候也要特別注意,如果是以臺灣的使用者為目標客群,戶 字應該要優先設計,如果僅設計 户 字的碼位,對於臺灣的使用者與慣用的輸入法來說,該字型檔其實是缺字的。反之,若以日本人為客群,則應設計 戸 字。
與漢字類似的地域差別
這種相同碼位、不同字形的現象,除了東亞漢字之外,在歐文中也有類似的情形。以俄語和保加利亞語為例,兩者雖然都使用西里爾文字,但兩國傳統上使用的字形卻不太相同。
這其實是一件相當有趣的事。源自於九世紀保加利亞第一帝國、用來紀錄古教會斯拉夫語的西里爾字母,在 18 世紀後期,被俄羅斯沙皇彼得一世魔改字母外觀後,隨著俄羅斯帝國和蘇聯的勢力擴張,反而鳩佔鵲巢,成為了目前「正統」西里爾字母的樣子。

保加利亞民間一直有在倡議使用保加利亞形式的西里爾字母,而最近俄羅斯和烏克蘭的抓馬,讓文字也牽扯到了民族情緒,變成了一個更複雜的問題。
只能說 Unicode 的這個規定雖然能大幅簡化了碼位的需求,卻為設計師與工程師帶來了新的挑戰;而這些文化與人文的微小細節,就是用心與否的關鍵所在。
本文同步刊於 iThome。詳見DAY 07 | Unicode 收錄的漢字狀況。