[Tech] OpenType 的 Feature
如之前所介紹的,做為格式的集大成者,OpneType 繼承了 PostScript、TrueType、AAT 格式的許多概念,其中影響最大的就是特性(feature)的調用。
對於設計師來說,如果想要設計一套優秀的字型,適當的引用 Feature 功能可以讓效果事半功倍;而 Feature 也將字型擴充了好幾個層次,是豐富字型功能及渲染結果的好幫手。
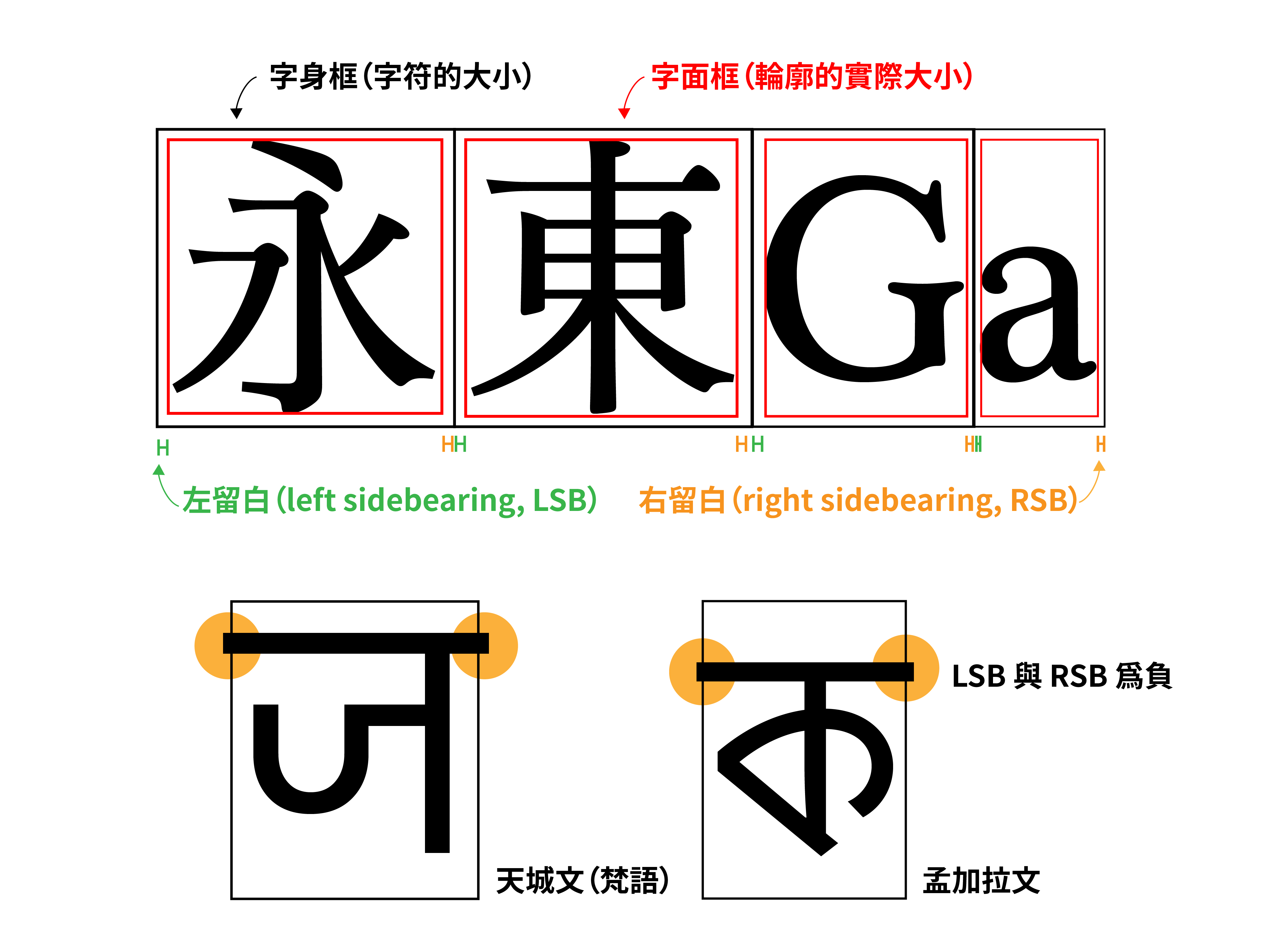
間距留白(sidebearing)
以漢字或是英文(這裡只討論印刷字)這種一個一個字書寫的文字為例,雖然不是很明顯,但字與字之間是存在留白空間的。字符本身並不會塞滿整個「字身框」(也就是實際字符的大小,通常是 1000x1000 或 1024x1024),而是會刻意地往內縮小一點。
我們將字型輪廓本身的外接矩形稱作「字面框」,以漢字來說,字身框的大小注定會比字面框來得大。而字面框與字身框在左右留下的間距,便被稱作左留白(left sidebearing, LSB)與右留白(right sidebearing, RSB)。
對大部分的語言來說,左留白與右留白的大小是一個正值,代表字與字之間有一個曖昧的留白空間。但對於一些需要「連著」書寫的字母來說,為了讓輸入的文字不會看起來是斷著的,字型本身其實是允許字面框超出字身框,也就是將留白值設為負值的。這類的代表以婆羅米系文字(Brahmic scripts)為主,像是天城文(用來書寫梵文)、孟加拉文等,就擁有一條上橫線(這條線被稱作 शिरोरेखा [śirorekhā]),將字與字串接起來。
字間微調整(Kerning, kern)
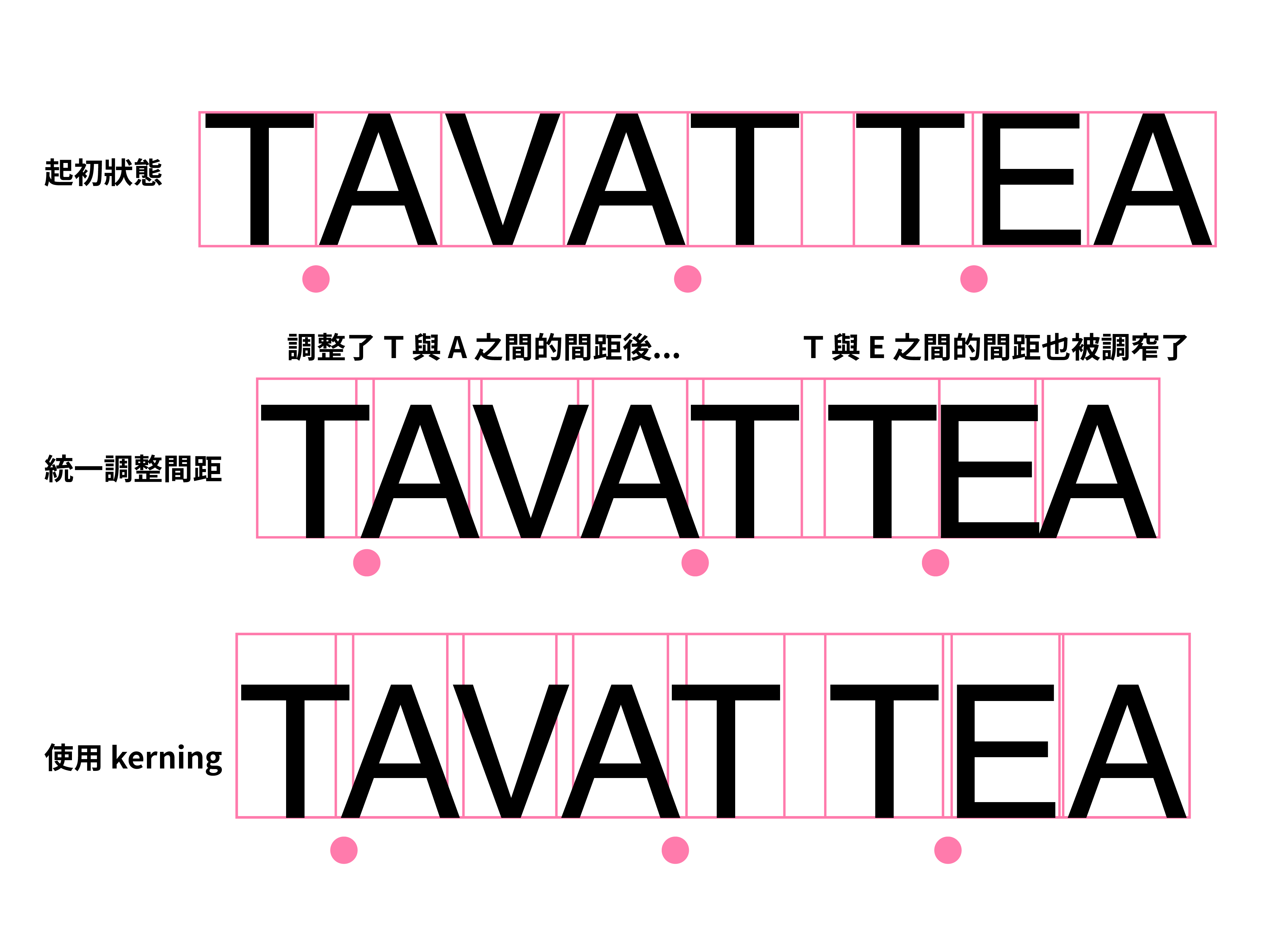
然而,即使我們已經調整了左右間距,把字符排在一起的時候,偶爾還是會有一些彆扭的空間,如下面的 TAVAT 字樣,每個字中間都好像被切開了,完全沒有一個詞的感覺。
這時候你或許會想到,喔那就像上面說的一樣,將他們的留白設為負值就好了,這樣 T 跟 A 之間的距離就會因為負值而縮小了!但接下來你面對了 TEA 這個字,完蛋,如果把 T 的右留白調成負數,那接著的 E 就會被吃到了,三個字反而疊在一起。
在過去的鉛字時代,鑄字師會特意鑄造不同留白的活字,可以按照前後文選擇要使用哪一個,並對內文的排版進行調整。這個動作被稱作 kerning。如下圖所展示的 p 與 s,可以看出他們的輪廓實際上是超出鉛字本身的。

而在現代的數位字型檔案中,我們也可以指定「字符對(glyph pair)」 kerning 的 feature,舉例來說,指定 T 與 A 兩個字符相鄰時,調整兩者之間的留白;但不指定 T 與 E,如此一來,在輸入 TEA 時就不會發生留白被吃掉的問題。
通常來說,大多的瀏覽器的 kerning feature 都預設開啟,所以其實不用特別設定,但如果想要手動調用的話,可以透過以下 css 啟用
.class {
font-kerning: normal;
-moz-font-feature-settings: "kern";
-webkit-font-feature-settings: "kern";
font-feature-settings: "kern";
}在目前的字型設計軟體中,kerning 的距離都可以分開來設計,讓字與字之間的曖昧距離更加自然。不過,受限於設計,有些字符對即使設定了 kerning,也會看起來怪怪的,此時,鑄字師會近一步鑄造一個「連起來」的字模,也就是連字(ligature)。

標準連字(Standard Ligatures, liga)
以拉丁字母來說,最常見的就是襯線字體的 f 在遇到另一個 f、或是遇到 i 時,即使把兩邊的留白都調為負數,仍然會看起來怪怪的,上面的垂頭會有沾黏的感覺,此時就會需要額外製作 f_f 或是 f_i 字符。

此時,渲染引擎會調用 OpenType 裡的 liga feature,讓 f與 i 的字符「替換」成「f_i」。這個轉換只會改變「選染出來的字符外觀」,在記憶體裡面還是儲存著 f 與 i,因此,在搜尋與比對的時候,依舊可以找到 f 與 i。
總而言之,liga 只會改變渲染的結果,並不會改變文本的內容。
為了使排版更美觀,歐文字型幾乎都會製作 liga 的字符,而在大多數的文書軟體與瀏覽器中,標準連字預設都是開啟的。但如果想要手動調用的話,還是可以透過以下 css 啟用:
.class {
font-variant-ligatures: common-ligatures;
-moz-font-feature-settings: "liga", "clig";
-webkit-font-feature-settings: "liga", "clig";
font-feature-settings: "liga", "clig";
}那麼中文呢?和歐文不同的是,漢字的可組合性在民間創造了諸如「招財進寶」、「孔孟好學」、「日進斗金」等「合文」——其實也能算是一種連字,只是有時候我們更常把他們當成是一個符號來看,畢竟我們還是習慣看到「招財進寶」四個字,但如果你想讓這些字以連字的方式實現,可以嘗試將他們設定成 dlig,也就是接下來要介紹的可選連字。
可選連字(Discretionary Ligatures, dlig)
選擇性連字是指那些非必要的、額外用來增加裝飾感、或是讓使用者自行決定是否使用的連字。
較著名的 dlig 如 c_k、c_t、s_t 等字符對。這些字符對的歷史其實已經相當悠久,當時的設計師想要刻意模仿沾水筆的書寫,而將兩個字符加上連筆。不過,如果不熟悉傳統歐文書法的人可能會「誤判」這些連字,在某種程度上造成閱讀的困難,因此他們通常都是「可選」的,要使用的話必須要考慮目標受眾。

此外,如果你有設計上的特別需求,也可以設計自己的 dlig,像是上面提到的「招財進寶」合文等。而大多數的瀏覽器和文書軟體都將 dlig 預設為關閉,需要使用的話必須額外開啟:
.class {
font-variant-ligatures: discretionary-ligatures;
-moz-font-feature-settings: "dlig";
-webkit-font-feature-settings: "dlig";
font-feature-settings: "dlig";
}歷史連字(Historical Ligatures, hlig )
歷史性連字主要是用來紀錄古籍或經典裡面的連字字符。如果想讓設計的字型更有復古的感覺,可以嘗試設計 hlig。
舉例來說,s 這個拉丁字母在八世紀盛行於歐洲的卡洛林小草書體裡(Carolingian minuscule),其實也可以長成ſ 的,因為他的筆畫看起來很長,所以又稱 long s(與之對比,現代的稱作 short s),通常用在詞首以及詞中,不置於結尾。

雖然後來的拉丁文字已經不再使用 ſ ,僅留下 s 的形式,但 ſz 的草寫在日耳曼地區演變成 ß (Eszett) ,成為現今的德國使用的標準德文字母之一(不過在瑞士與列支敦士登,瑞士標準德文並不使用 ß,而是直接拼成 ss)。
和 dlig 一樣,大多數的瀏覽器和軟體都預設 hlig 為關閉,需要的話得額外啟用才行:
.class {
font-variant-ligatures: historical-ligatures;
-moz-font-feature-settings: 'hlig';
-webkit-font-feature-settings: 'hlig';
font-feature-settings: 'hlig' on;
}小寫轉小型大寫字母(Small Caps, smcp)
小寫的出現
我們對大寫與小寫的存在可能已經習以為常,畢竟多數人從小就開使學習英文了,長大之後可能會多學法文、德文、西班牙文,甚至是俄文、希臘文等歐洲語言作為第 n 外語。不過,綜觀世界上大多的書寫系統,除了上面提到的拉丁文字、希臘文字與西里爾文字之外,大寫與小寫的概念其實相對罕見。
早在兩千多年前的羅馬帝國時期,拉丁字母是僅有大寫形式的——既然不存在小寫形式,這裡區分大跟小其實也沒有意義——因此目前義大利的古蹟石碑上的刻文都是大寫。在後來漫長的黑暗時代裡,經典的繼承與複製大多由修道院的抄寫員(Scribe)負責,此時,雖然已經有一些「看起來像小寫」的字母出現,但他們大多還是以大寫為基底、揉合抄寫員自己的風格的草寫樣式,並不存在真正意義的「小寫」。

時間來到八世紀中,矮子丕平(Pépin le Bref)在教宗和貴族的支持下,推翻了法蘭克王國的墨洛溫王朝(Mérovingiens),建立起新的加洛林王朝(Carolingiens)。後來,其大兒子查理曼(Charlemagne)與小兒子卡洛曼(Carloman)繼承法蘭克王國;而在弟弟卡洛曼驟逝後,查理曼獨攬皇權,並在東征西討後統一西歐,由教宗加冕為大帝。這是繼西羅馬帝國在西元 476 年滅亡後,歐洲再次出現大一統的政權。
伴隨著政權局勢的統一,查理曼大帝開啟了後來被稱作「加洛林文藝復興(Carolingian Renaissance)」的文化運動,其中目標之一便是文字改革,目標是創造一種清晰、易讀、好書寫的字體——畢竟當時拉丁文使用的大寫公文書體晦澀難懂,稍微讀過書的人都不一定看得懂了,何況是不識字的人——後來,這套被創造出來的字體,被稱作卡洛林小寫字體(Carolingian minuscule),並隨著加洛林文藝復興的浪潮被推廣到王國各處,成為後世小寫字體之祖。

到了活字時代,因為小寫使用頻率比大寫還要高,因此會被放在鉛字盤靠近下面的地方,方便檢字員快速找到需要的字母,因此被稱作 lowercase;相對的,因為大寫字模會被放在上層、離檢字員較遠的地方,因此才被稱作 uppercase。
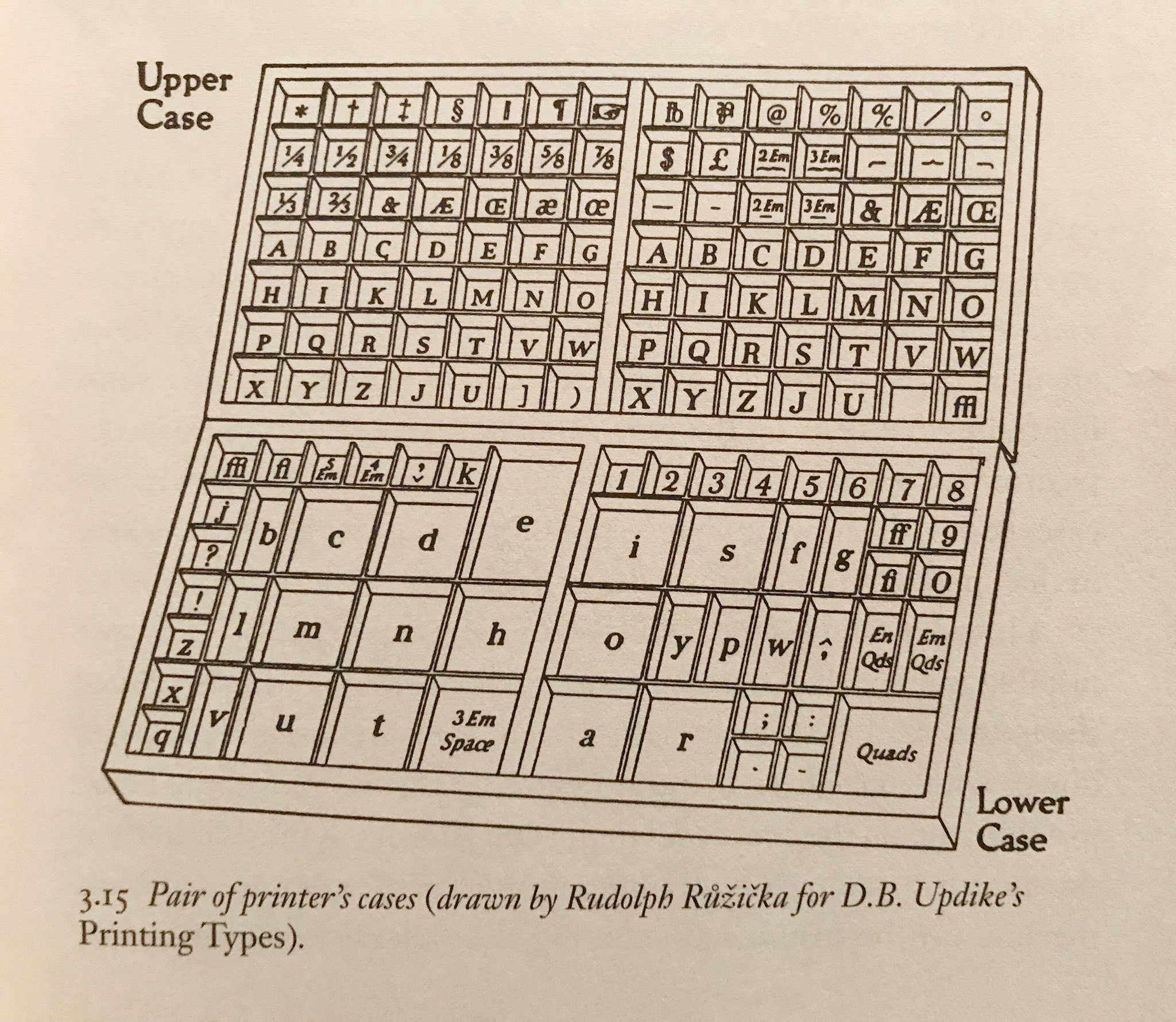
小寫轉小型大寫字母顧名思義,是把「小寫」轉成「小型大寫字母」,其中,小型大寫字母的大小比標準的大寫還要更小(這裡指的是高度),但會比小寫來得大。
小型大小字母通常用在強調內文。和一般的大寫相比,小型大寫字母的「強調」比較自然,不會很突兀。如果看過歐美漫畫的話,應該會發現全大寫的文本其實很難閱讀。
拉丁字母的大小寫轉換大家應該都很熟悉了,但仍然要格外注意字型的使用客群。舉例來説,在英文裡 i(U+0069)和 I(U+0049)是一組的,但在供土耳其語使用的土耳其拉丁文字裡,大寫 I (U+0049)的小寫是 ı(U+0131,上面沒有一點),而大家常以為的 i(U+0069) 的大寫其實是 İ(U+0130,上面有一點)。也因為這樣,所以在土耳其文中,f_i 連字應該禁用。

.class {
font-variant-caps: small-caps;
-moz-font-feature-settings: "smcp";
-webkit-font-feature-settings: "smcp";
font-feature-settings: "smcp";
}大寫轉小型大寫字母 (Caps To Small Caps, c2sc)
和 smcp 相對的,如果想把「大寫」轉成「小型大寫字母」,則需要增加 c2sc 特性。

.class {
font-variant-caps: all-small-caps;
-moz-font-feature-settings: "c2sc", "smcp";
-webkit-font-feature-settings: "c2sc", "smcp";
font-feature-settings: "c2sc", "smcp";
}花飾字(Swash, swsh)
通常在設計歐文手寫書法字型的時候,會額外設計用來替換大寫字符的花飾字符,總而言之用了就會很浮誇,很適合用在標題的設計。

.class {
-moz-font-feature-settings: "swsh";
-webkit-font-feature-settings: "swsh";
font-feature-settings: "swsh";
}預設文體替代字 (Stylistic Alternates, salt)
我們之前在介紹 Unicode 的時候,曾經提到 Characters, not glyphs 原則,即讓字型決定該字符的樣子。
於是,我們可以在一些襯線字體裡面看到雙層的 a 和 g、而在非襯線的字體裡面看到單層的 a 和 g——但我們可不可以在同一套字型裡面放兩種寫法?還是說這兩種「造型」其實應該要分開編碼?
根據 Unicode 的 Unification 原則,這兩種「造型」純粹只是因為手抄員流傳下來的習慣、或是設計師的風格才會如此,本質上都是同一個字,因此僅會有一個碼位。
為了讓同一個碼位可以「選擇性」的調用某個「造型」,我們可以在同一個字型檔案裡面,打包兩種不同造型的字符,並透過 salt 特性讓使用者決定要使用哪一個。

.class {
-moz-font-feature-settings: "salt";
-webkit-font-feature-settings: "salt";
font-feature-settings: "salt";
}文體集(Stylistic Sets, ss01…ss20)
有了 salt,那我們可不可以更進一步,放入更多不同「造型」的字符?答案是可以的。
OpenType 定義了 ss## 的文體集(可以想成是同一個字、但不同風格的集合),在一個字型檔案裡,每個字符最多可以放入 21 種不同的造型(本體 + ss01 ~ ss20)。所以,其實你可以把襯線造型跟非襯線造型打包在同一個字型檔案裡面——只是通常不會有人這麼做。
通常來說,salt 會使用 ss01 的字符,可以把 salt 當成是文體集的預設形式。

.class {
-moz-font-feature-settings: "ss01";
-webkit-font-feature-settings: "ss01";
font-feature-settings: "ss01";
}上下文替代(Contextual Alternates, calt)
上下文替代,是會依照該字符的上下文語境(context)去判斷是否需要替換。換句話說,此 feature 是存在邏輯判斷的。舉例來說,像是 j、q、g、y 這些擁有下降部(descender)的拉丁字母,如果同時出現在一起的話,下面可能就會擠在一起,可是和其他字符並排時又看起來好好的。
此時,我們就可以透過 calt 來指定當「特定字符一起出現時」,替換其中的某個字符。
以下面為例,當 g 和 j 接連出現時, j 的下面會太靠近 g,完全沒有留白空間。但我們又不想改動原本 j 的造型,如果是調整 kerning 的話又會相鄰太遠。
這種情況下另外製作 g_y 的 liga 當然也是一種解法,但我們也可以透過 calt,當 g 出現在 j 前面時,將後面的 j 改成 j.ss01,也就是另外一種文體的 j。反之,如果沒有相鄰,就讓兩個字都保持原本的設計即可。

calt 通常預設也是關閉的,需要透過 css 啟用:
.class {
font-variant-ligatures: contextual;
-moz-font-feature-settings: "calt";
-webkit-font-feature-settings: "calt";
font-feature-settings: "calt";
}更多玩法
上下文替代(與其類似的 feature 族)可以說是 OpenType 最有趣、最多變化的特性,沒有之一。只要能好好的設定,就能做出許多意想不到的功能。
例如之前 justfont 在愚人節推出的「就是不錯字(吧)」,就是透過判斷一組「詞」的字詞來替換。
以 ㄒㄩㄣˊㄨㄣˋ 二字來說,正確的寫法應該是 詢問 二字,但常常會有使用者打成 尋問。此時,我們就可以透過 calt 特性,讓字型判斷當 尋 跟 問 出現在一起的時候,將前者的 尋 替換成 詢;而若兩者沒有放在一起的話,就保持原狀就好。
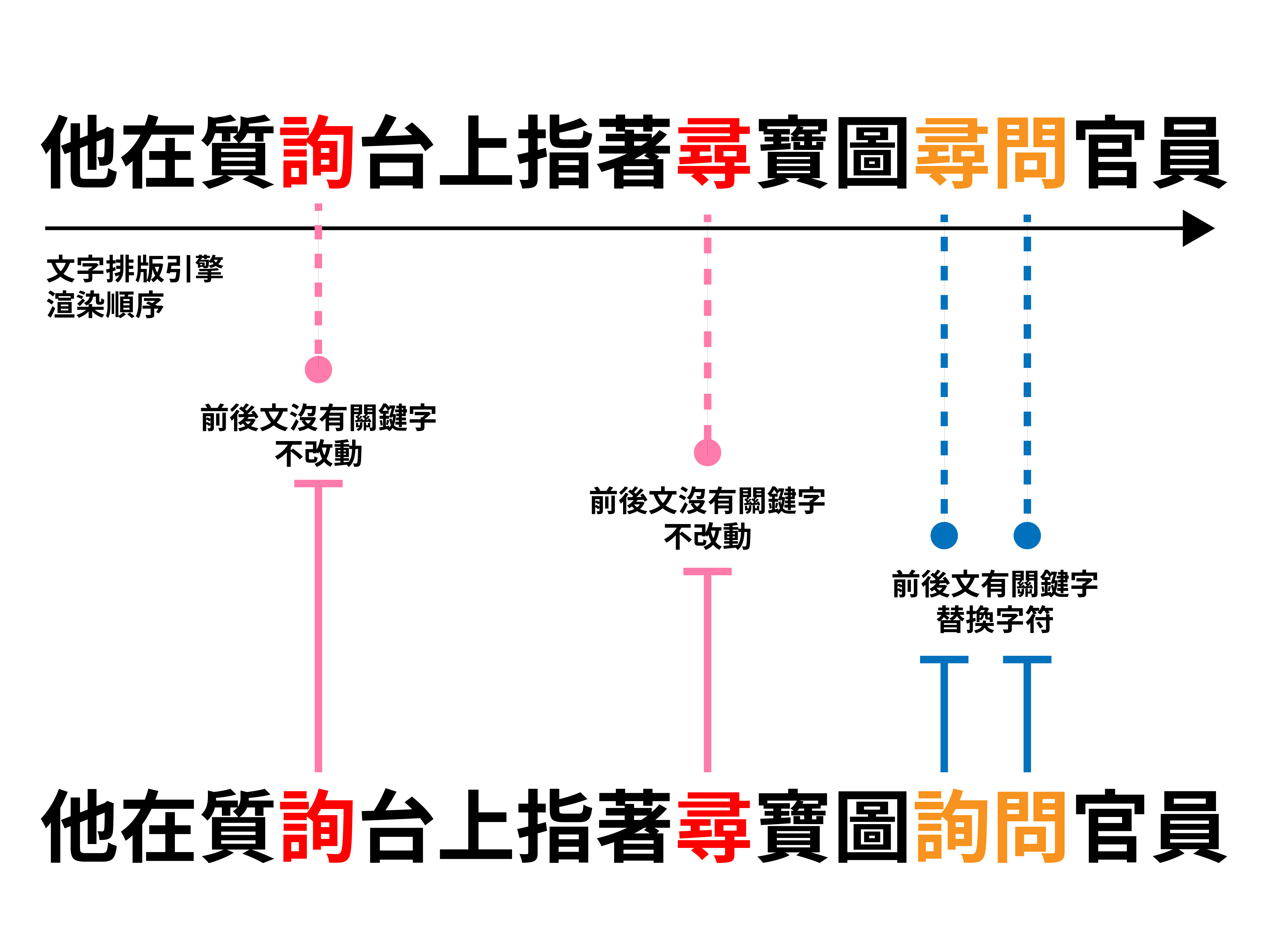
不過呢!即使已經從上下文來決定要不要替代,但有時候還是要處理例外狀態,萬一有使用者想輸入 千尋問鍋爐爺爺能不能在這裡工作 這樣的字怎麼辦?如果什麼都不管的話,千尋 就變成 千詢 了,此時,就必須另外撰寫例外原則,我們在更之後的日子裡會更進一步的探討這個議題。
另一個例子是,有許多號稱簡體轉繁體的字型(許多裝置不允許線上翻譯,此時直接換字型是最快的),其實就是在簡體中文的碼位裡內放入繁體中文的字形,但由於簡體字和繁體字並不是一對一映射的關係,常常會出現 皇後、辛醜年 這樣的機翻笑話,如果可以透過詞庫來組成 calt 規則,便能解決類似的誤會。
總之,在使用 calt 這種帶有邏輯、會考慮上下文字的 feature 時,最好對該語言和文字有一定程度的理解——在使用科技之餘,也不應該罔顧人文——否則就會出現笑話了。
豎排(Vertical Alternates, vert)
歐美各國所使用的書寫系統皆是橫排為主,因此在顯示終端剛出現、對字型顯示需求剛誕生的時候,都只有考慮到橫排的狀況。但在東亞,扣除在近代廢除豎排的簡體中文,繁體中文與日文、韓文一直都有豎排的文化。
對於「僅」使用漢字、日文假名、韓文來排版而言,無論是橫排還是豎排,每個「方塊字」都可以像積木一樣的疊得好好的。但如果今天必須和標點符號、數字、歐文等文字混排,那麼豎排時要考慮的項目就會變成相當複雜。
通常來說,我們會讓半形的數字與歐文跟著旋轉 90 度,而全形的數字和歐文則不旋轉——好消息是,目前多數的文書軟體都有辦法做到這件事情;不過,標點符號就必須個別設定,例如全形句點 , 不旋轉,而全形引號 「 和 」 則必須另外設計一個旋轉九十度的樣子。
大多數 CJK 的字型都會特別設計豎排的符號——這就是我們的工作了。
在文字從橫排改成豎排時,會先把所有的文字都旋轉 90 度,接著分辨哪些是需要轉正的(例如漢字、假名、全形字符),再將其旋轉回來。最後,透過 vert 表,將表內給定的標點符號替換成 vert 版。

豎排・改(Vertical Alternates and Rotation, vrt2)
做為 vert 的改版,vrt2 會先把全部的文字都旋轉 90 度,並再次將所有的文字旋轉回來(其實就是都排成正的),並透過 vrt2 將指定的字符「再轉回去」。
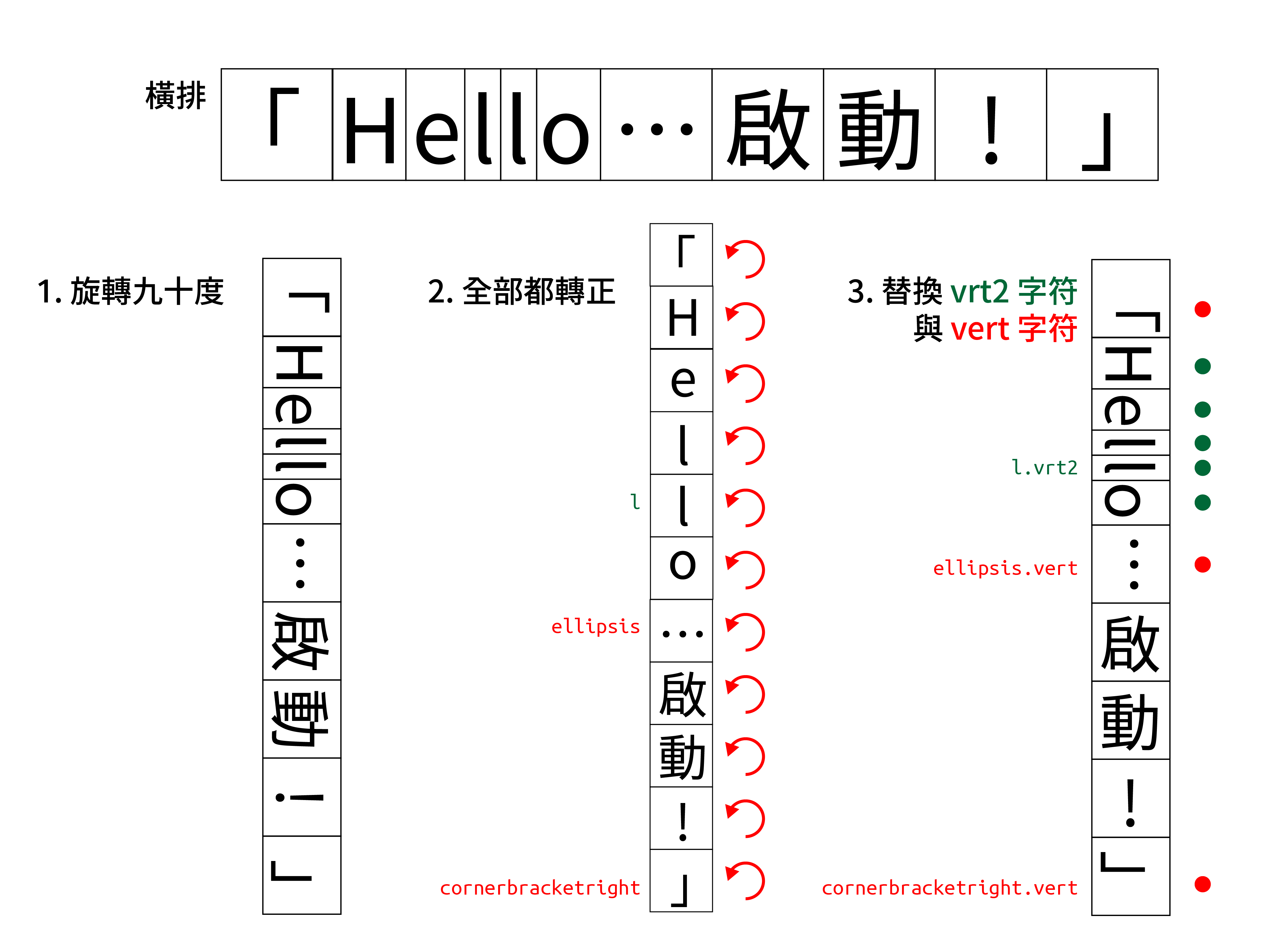
兩種轉換方式的差別在於,vert 在分辨哪些是不需要轉正的字符時,其實是相當模糊的。你或許會問,不就是把全形的字符轉回來嗎?拉丁文字確實是有將半形和全形的字符分開編碼,但像希臘文字與西里爾文字都僅有一個碼位,並無特別區分全形與半形。
這些字符要做成全形的尺寸(和漢字一樣寬)、還是做成半形的尺寸,都是各家字型廠商所決定的,所以有機會判斷錯誤。與之相比,vrt2 預設所有的字符都是正的,誰要旋轉則由 vrt2 控制,這相當於列了一個白名單,把旋轉與不旋轉一事交還給字型決定。
瀏覽器預設的 vert 和 vrt2 為關閉,不過在開啟之後,若該字符同時有 vert 和 vrt2 時,會優先使用 vrt2。
.class {
-moz-font-feature-settings: "vert";
-webkit-font-feature-settings: "vert";
font-feature-settings: "vert";
}字符分解與組合(Glyph de/composition, ccmp)
到目前為止,無論是把一換一(smcp, vert, calt, swsh, ss01)或是多換一(liga, hlig, dlig),都是「字符」對「字符」之間的變化——那如果是「變音符號(Diacritic)」與「字符」呢?
依舊拿法文和德文來舉例,像是有一撇(尖音符,Acute)的 é 和有兩點(元音變化符,Umlaut)的 ü 又該怎麼處理?
在原始的 ASCII,也就是英文字母裡,是不存在這些變音符號的(至於為什麼在英文裡沒有使用變音字母呢?這可是另一個語言學的大問題),但隨著編碼的擴充,為了配合不同的語言需求,便在拉丁字母擴展區中塞入了不同的變音字母,例如上面提到的 é 或是 ü。
不過,Unicode 很快就意識到,收錄所有變音字母的想法實在太過天真,畢竟變音符號這種在任合字母上都可以加上去的東西,有時候還不僅限於只加一個,有需要的話可以無限的上疊,產出的組合可以説成千上萬——光是一個 a,就 至少 可以組出 áăắặằẳẵǎâấậầẩẫäạàảāąåǻã 共 23 種變化——甚至,你也可以在漢字上面標記變音字母,雖然沒有人會這樣,但也沒規定不行這樣做。
因此,Unicode 在 U+0300 - U+036F 區域預作變音符號,允許任意字母和這一區的變音符號進行組合。這一區的變音符號除了上面提及的拉丁字母之外,也收錄了希臘字母的變音符號、日文的濁點與半濁點、希伯來文的尼庫德(Niqqud)記號等。
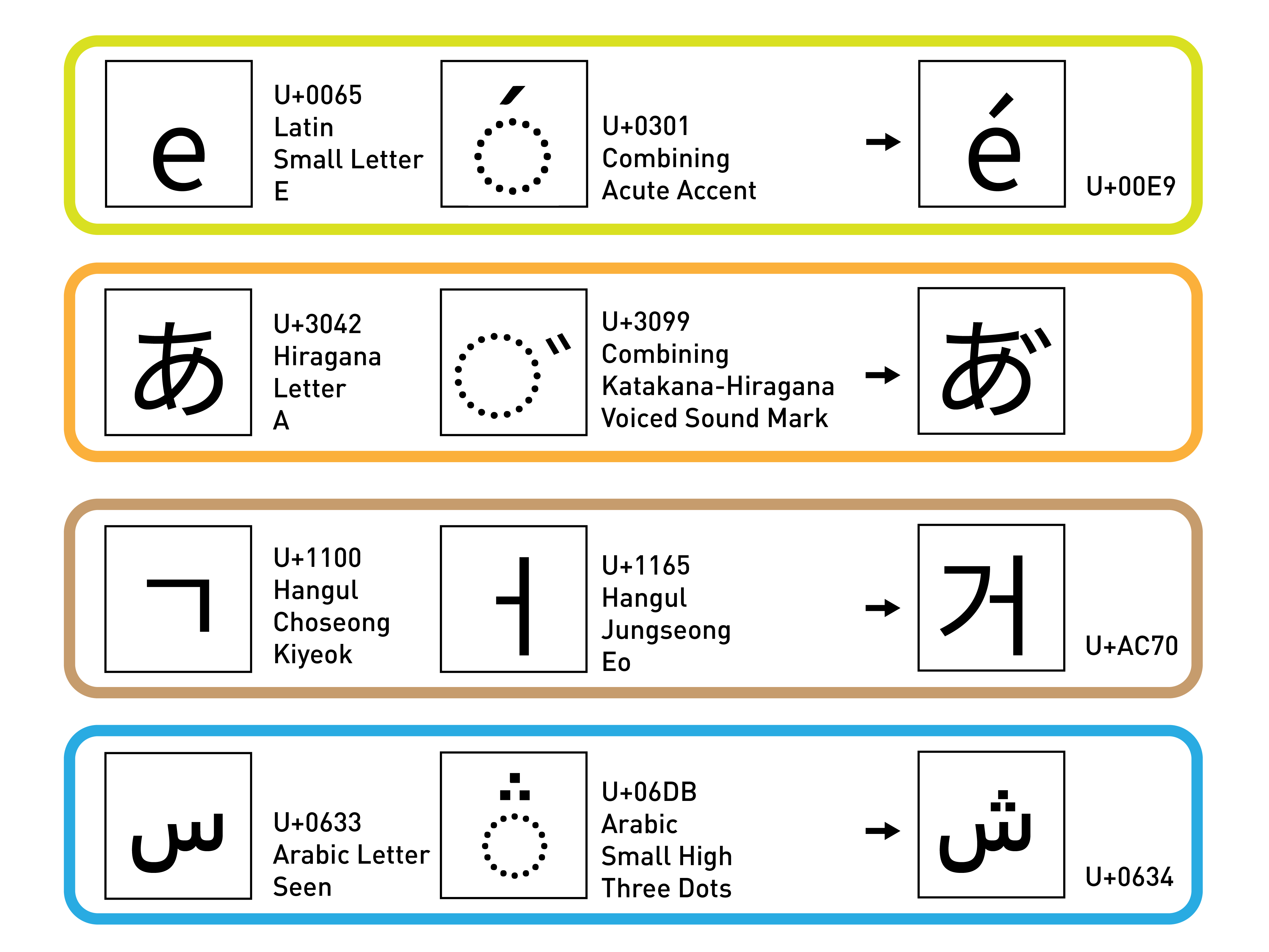
透過 ccmp,我們便可以「製作」出沒有被收錄在 Unicode 裡面的變音字母,例如台羅拼音的第八調調號字符。因此,ccmp 也是一種替換。
通常來說,軟體與瀏覽器會強制使用 ccmp,只要有好好設定(言外之意就是很多字型其實都沒有正確的設定),字符與變音符號就能透過該表進行「合體」。
.class {
-moz-font-feature-settings: "ccmp";
-webkit-font-feature-settings: "ccmp";
font-feature-settings: "ccmp";
}但為了讓那些不支援 OpneType 的陽春文書軟體亦能正常顯示,變音符號的字符寬度通常會設為 0,讓變音符號可以和字符相貼在一起。即使沒辦法讓變音符號出現在正確的位置,但至少可以大致上知道該字是一個變音字母,不至於造成歧異。
無限變音符號
此外,變音符號的使用不僅限於一個,每次組合起來的變音字母都可以在和新的變音符號再組合,理論上,是可以無限添加在子母上的。有時候會在網路上看到像是 「Ȟ͙̰̜̠͚̈̀̈̓̋̀̾̐e̱͔̝̞̬̘̩̽̋͋̑̀̌̆͊̐̋l̝̝͕̦͇̪͚̱͙̲̠̦͊̆̋́̇l̰̥̞͓͙͇̬̦̽̃̐͂̒̿͊̒͊̃̌̾ǒ͎̞̰̝̬̥͎̝̞͔̖̏͊͛̊͂̀̆͗͛͗̄ W̖̗̬͓̤͚̞̋́͊͆̇̇͑̓̈̾̚ͅo̳̲̤̩̭͇̓́̏̎̀r̥̣͓͍̊́̏̾̾́̌̐d͓̰̥̠͕͉͇̜̝́̎͌̉̾̈́̉ͅ」這樣的迷惑字母(稱作 Zalgo),就是運用了符號組合的 ccmp。
韓文?
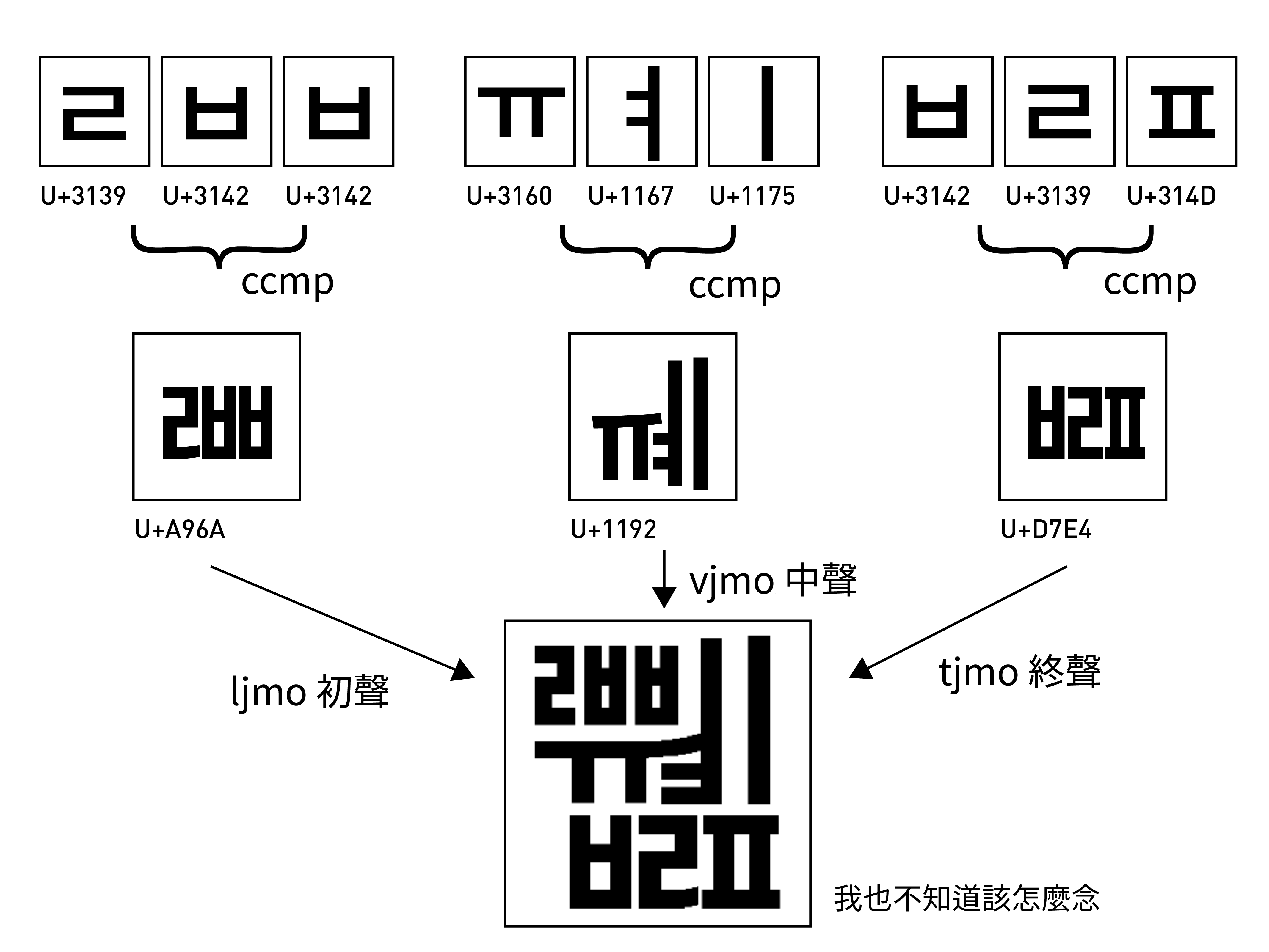
在現代韓文字母(Hangul Jamo)中,共有 19 個初聲(자음,子音)、21 個中聲(모음,母音)、28 個終聲(종성,27 個子音組合以及「沒有」),排列組合之後總共有 192128 = 11,172 種可能。
在這 11,172 個字母組合中,又有許多發音饒舌、結構奇葩的韓文是不會使用到的,實際生活中大概只會看到 1,200 多種字母。舉例來説,빪 [ppal] 應該已經是目前正在使用的韓文裡最複雜的了(빨다 - 「洗」的名詞形);更複雜的像是 쬂 [jjwaelt] (我也不會念),就只是在拼字邏輯上合理、但現實生活不可能用到的字。
面對這 11,172 的組合,如果使用 ccmp 實現組合,便只需要佔用 19+21+28=68 個碼位就好,那為何 Unicode 還是為每個可能出現的韓文都分配了單獨的碼位?雖然有謎之八卦指出是韓國的施壓,但我想還是為了配合當初韓國廠商施行已久的 KS X 1001 編碼、以及當年 OpenType 支援度還未普及的關係。
在歷史上,1991 年最初釋出的 Unicode 1.0 中,在 U+3400 - U+3D2D 區域收錄了 2350 個常見韓文、隔年 1.1 又再增加 4306 個韓文(佔用 U+3400 - U+4DFF)。這個時間點剛好是 OpenType 剛誕生的時候,對組合的支援性還未普及,因此 Unicode 最後還是決定獨立收錄所有組合結果。於是,在 1993 年 的 2.0 版本中,韓文被搬遷到 U+AC00 - U+D7AF 區域。原本的碼位改收錄 CJK 擴充 A 和易經八卦符號——這也是為何擴 A 的碼位會比基本區還前面的原因,也是 Unicode 極少更改碼位的事件。
當然,這不代表我們不能用 ccmp 來組韓文,如果你瀏覽器的字型(像是思源系列)有支援 OpenType ccmp 的話,각(U+AC01)和 각(U+1100 / U+1161 / U+11A8)看起來就 應該要是一樣的。反之,若你看到後面的 [gag] 是三個字母,就代表你的字型並沒有特別映射 ccmp。
至於更複雜,至多包含 124 個初聲、94 個中聲、137 個終聲、2 個旁點,理論上可以同時合併九個部件,多達 1,638,750 種組合可能的古韓文與方言…恩…面對連 Unicode 都放不下的數量,就只能先使用 ccmp 組合、再使用 Unicode 裡額外的 ljmo (Leading consonant Jamo)、vjmo (vowel Jamo) 和 tjmo (trailing Jamo) 特性顯示了——其中大多的結果只是為了展現韓文的組合邏輯和可組合性,歷史上根本不會使用到。
歷史遺留問題
目前,因為我們已經可以透過變音符號區自由的組合出字母,因此 Unicode 已經明確的表示不會再收錄新的變音字母。不過,那些在早期已經收錄的字母,因為 Unicode 原則的 Stability,其碼位也不會被移除。
此時,就有可能遇到一個問題,在早期被收錄在 Unicode 裡面的變音字母,例如 é(U+00E9),其實也可以透過組合的方式,以 e(U+0065)與 U+0301 來表示。雖然兩者「看起來」是一樣的,但記憶體裡儲存的碼位其實是不同的。
因此,若要執行搜尋與比對,和前面提到的未統一漢字相同,必須要將兩者透過正規化方法進行整併。
本文同步刊於 iThome。詳見DAY 08 | OpenType Feature (1):Kerning、DAY 09 | OpenType Feature (2):連字系列、DAY 10 | OpenType Feature (3):字母系列、DAY 11 | OpenType Feature (4):上下文替代、DAY 12 | OpenType Feature (5):豎排、DAY 13 | OpenType Feature (6):組合字符。