[Tech] Emoji
像是 :( 、:-) 這樣的表情符號(emoticons)其實已經出現很久了,其辭源來自於表示 emotion(情緒)的 icon(符號)。
不過,現在狹義上指稱的 Emoji,得追溯回 1999 年的日本,NTT DOCOMO 的工程師栗田穰崇在 12x12 的網格上設計的 176 個符號,用來表達天氣狀況、食物、以及星座等意思——這裡的 Emoji,辭源是來自於「絵(え [e])文字(もじ [moji])」——話說不少人以為那個 E 跟 E-mail 的發音一樣,把他讀成「以摸幾」,但從本質來看,Emoji 的發音應該要是「誒摸幾」才對——不過語言是拿來溝通的,大家都聽得懂就好。

這裡最有趣的一點是,雖然 Emoticon 跟 Emoji 的辭源一個源自英文、一個源自日文,但拼法卻都很接近,指的也是差不多的東西。
在 2000 年時,便有人提案將這些可愛的小東西——在當時被稱作 NTT DoCoMo Pictographs——加入 Unicode 內(L2/00-152 提案),不過在當時的時空背景下,沒有人能保證這些小東西是不是真的泛用且能用,草案便沒了然後。
不過,這些彩色的小東西依舊受到日本人的喜愛,各家電信廠商也接連推出自己的 Emoji 符號集。在當時,每間公司使用的編碼集和標準都不一樣,為了讓不同廠商或手機的使用者可以在信件和訊息中互傳 Emoji,所以彼此之間約定了交叉的碼位映射表,用來解決相容性的問題。
這種辦法在日本境內或許還勉強可行,不過一但有國外使用者使用未約定映射表的設備瀏覽文章,Emoji 就會顯示出亂碼。
在 2006 年左右,Google 打算將 Gmail 引入日本,為了打入市場,必須優先解決 Emoji 編碼的問題,於是便率先使用了 Unicode 的 PUA 區段為 Emoji 分配碼位——但使用 PUA 的問題依舊在於,彼此需要事先約定,如果兩個機構的 PUA 區段有重疊的分配,勢必得搬遷其中一邊的碼位來滿足字符的顯示。
講來講去,沒有標準就是一個最大的問題。
另一方面,積極將 iPhone 引入日本市場的 Apple,也遇到了 Emoji 的編碼和顯示問題。於是,Google 與 Apple 兩科技大佬便決定聯手推動將 Emoji 添加到 Unicode 的提案(L2/09-026 提案)。雖然這中間受到了許多質疑,但 Unicode 最終還是於 2009 年的 5.2 標準中加入 114 個 Emoji,在隔年的 Unicode 6.0 中又加入了 608 個,並持續增添至今。
字符的長度與編碼
在繼續之前,我們先複習一下前面提到的 Unicode 編碼問題。一般而言,大多的顯示引擎都是採用 UTF-16 編碼,所以位於 BMP 上的字符都可以透過 2 個 Byte 表示、而位於輔助平面的字符,像是 CJK 擴充區的漢字,則需要透過代理對(surrogate pair)——一個高位代理、一個低位代理——共 4 個 Byte 表示。
而對於遵從 UCS-2 標準的 javascript 而言,會將 2 個 Byte 視為一個字符,所以我們可以透過 .length 和 .charCodeAt() 得到:
// 位於 BMP 且包含於 ASCII 區段的歐文
~"a".length > 1; // 2 Byte = 1 Character
~"a".charCodeAt(0).toString(16) > "61"; //U+0061
// 一般位於 BMP 的中文
~"我".length > 1; // 2 Byte = 1 Character
~"我".charCodeAt(0).toString(16) > "6211"; //U+6211
// 位於輔助平面的字符(這個長得很像鑰匙的字是 CJK 擴 B 區的)
~"𠁩".length > 2; // 4 Byte = 2 Character (?)
// 事實上,該碼位由兩個代理字符處理,所以
~"𠁩".charCodeAt(0).toString(16) > "d840"; //U+D840
~"𠁩".charCodeAt(1).toString(16) > "dc69"; // U+DC69

對於這種藉由代理對顯示、位於 輔助平面 的字符,我們可以透過碼位的加加減減,將代理對的碼位轉回實際的碼位:
function transferSurrogatePairToRealCodePoint (element) {
const comp = (
(element.charCodeAt(0) - 0xD800) * 0x400 +
(element.charCodeAt(1) - 0xDC00) + 0x10000
);
return comp.toString(16)
}
~ transferSurrogatePairToRealCodePoint('𠁩')
> '20069’ // U+20069
所以對 Emoji 這種同樣位於輔助平面的字符而言,其長度應該要為 2:
~"🍎".length > 2;
~transferSurrogatePairToRealCodePoint("🍎") > "1f34e"; // U+1F34E
不過如果我們繼續嘗試其他的 Emoji…
~"👱🏾".length > 4;
~"🇹🇼".length > 4;
~"❤️🩹".length > 5;
~"🧑🚒".length > 5;
~"👨👩👧".length > 9;奇怪?為什麼有的 Emoji 的長度不是 2?
那是因為有許多的 Emoji 其實是透過組合字符,也就是 ccmp 的 feature 來組合的,像是旗幟、膚色、家庭成員的組成、以及一些有趣的小東西們。我們可以透過點點點語法 [... ] 把這些 Emoji 展開來看看:
~[..."👱🏾"] > (2)[("👱", "🏾")];
~[..."🇹🇼"] > (2)[("🇹", "🇼")];
~[..." ❤️🩹"] > (4)[("❤", "️", "", "🩹")];
~[..."👩🚒"] > (3)[("👩", "", "🚒")];
~[..."👨👩👧"] > (6)[("👨", "", "👩", "", "👧", "")];膚色:菲茨派屈克修飾符
為何表情 Emoji 的膚色看起來這麼「黃」?—— 即使是最純的亞洲黃種人,膚色也不會是這麼不自然的顏色。這是因為 Emoji 在設計時, 為了讓其本身的意思相對「中立」,不會偏向白人、黃人、或是黑人,所以才挑選了這麼不自然的黃作為「表示人類」的膚色。
不過,為了讓人們可以自由地選擇膚色,在 Unicode 裡面,還是特別定義了五種用來修飾膚色的菲茨派屈克修飾符(Fitzpatrick Modifier),這是由美國皮膚科醫生 Thomas B. Fitzpatrick 於 1975 年提出的膚色色表。雖然仍有許多人批評其系統過時、刻板印象過深,但仍然因其相對簡單的定義而使用至今。

只要跟人類有關的 Emoji,或是出現過人類部位(手、腳、臉)的 Emoji,都可以透過 在 Emoji 後面 添加菲茨派屈克修飾符調整顏色,詳細的清單可以參考 Unicode 的文件。
ZWJ:零寬連字
零寬連字(Zero-width joiner, ZWJ, U+200D),顧名思義就是寬度為零的 連字字符,可以 「強迫」的將前後兩個字符連在一起 ,用在 Emoji 上便能憑空組合出不佔用碼位的 Emoji。
以剛剛的消防員(Firefighter Emoji)來說,其實是被定義成是「人」+「消防車」(這什麼腦洞大開的組合方式),所以我們可以透過 ZWJ 連接「人 / 🧑 U+1F9D1」與「消防車 / 🚒 U+1F6921,得到「(不分性別的)消防員 / 🧑🚒」、或是「女性 / 👩 U+1F469」與「消防車 / 🚒 U+1F692」,得到「女消防員 / 👩🚒」。
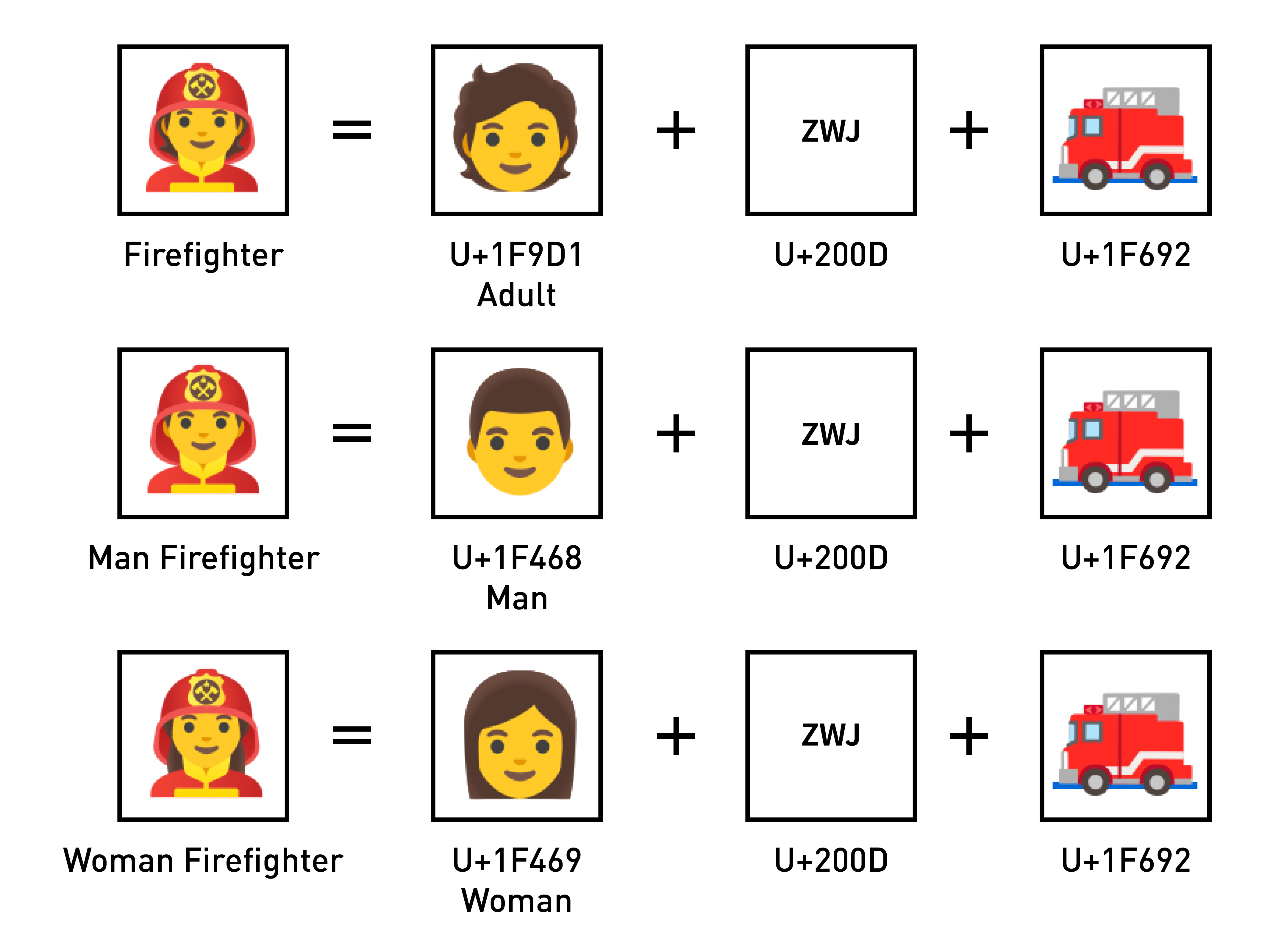
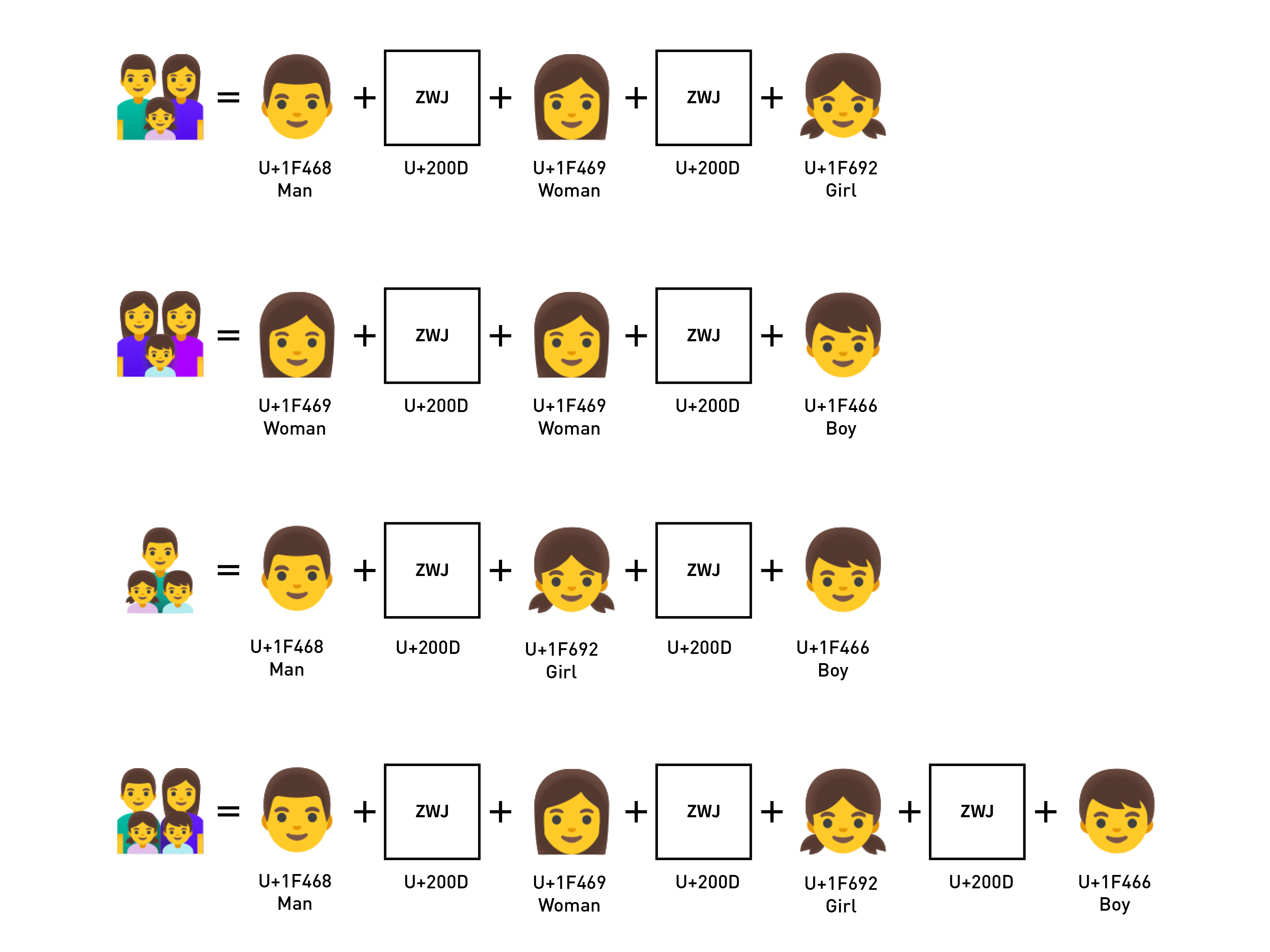
同理,我們也可以將人像用來組合家庭成員,如果我們定義「父親 / 👨 U+1F468」、「母親 / 👩 U+1F469」、「女兒 / 👧 U+1F467」、「兒子 / 👦 U+1F466」的話,就可以組合出各式各樣的家庭。
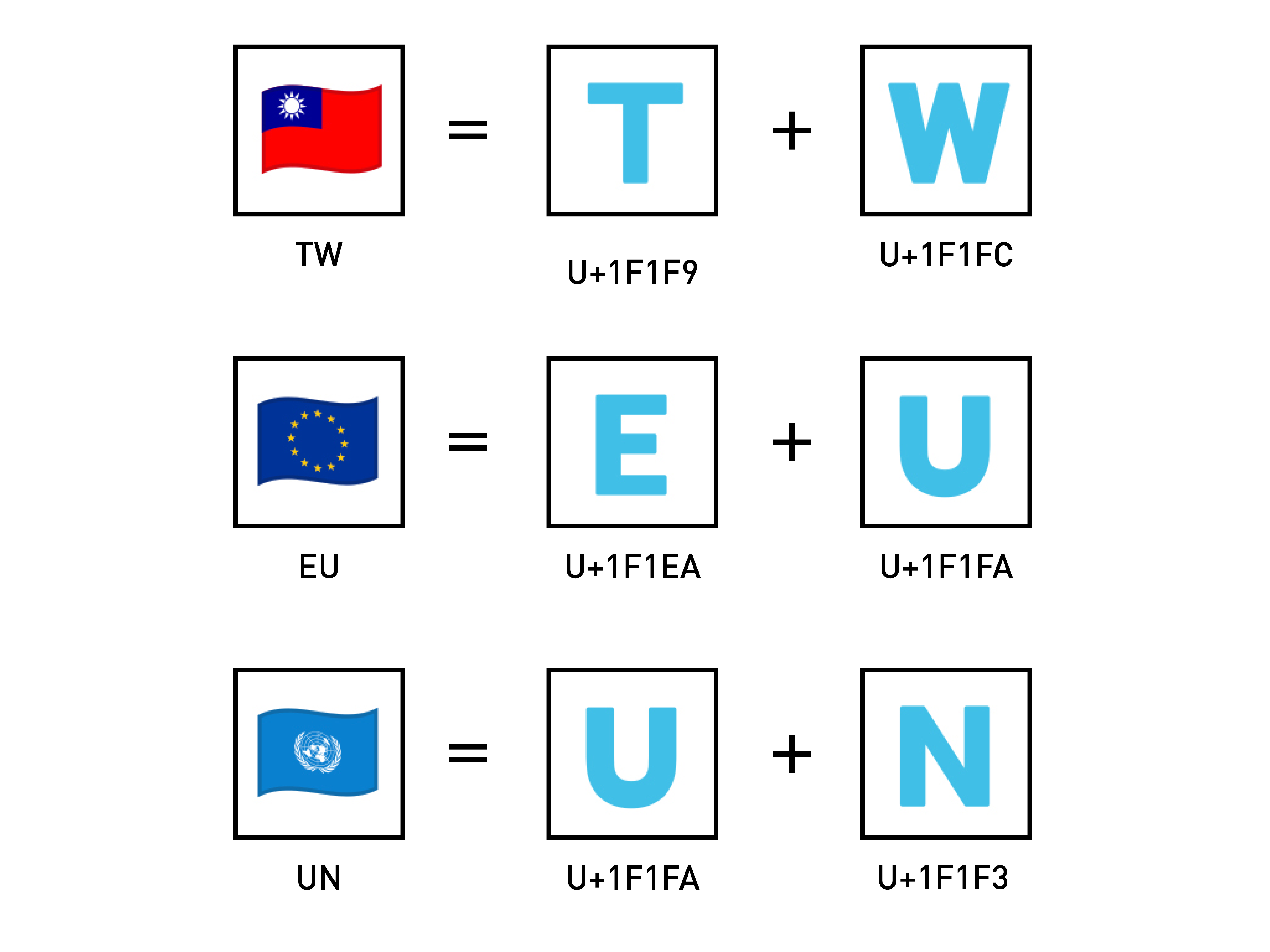
國家、地區和組織
此外,因為國家、地區和組織有可能滅亡或新成立,因此旗幟區的符號其實也是透過組合字符的功能實現的,我們可以使用 Unicode 的旗幟英文區段(U+1F1E6 - U+1F1FF)來拼寫國家、地區和組織的名稱,進而產生想要的旗幟。
feature 設定
ccmp 是一種多對一的轉換方式,也就是採用 LookupType 4 替換規則,這裡簡單的列出一些規則:
feature ccmp {
...
sub u1f471 u1f3fe by u1f471_1f3fe; // Person: Medium-Dark Skin Tone, Blond Hair
sub u1f9d1 u200d u1f692 by u1f9d1_200d_1f692; // Firefighter
sub u1f468 u200d u1f692 by u1f468_200d_1f692; // Man Firefighter
sub u1f469 u200d u1f692 by u1f469_200d_1f692; // Woman Firefighter
sub u1f1f9 u1f1fc by u1f1f9_1f1fc; // Taiwan Flag
sub u1f468 u200d u1f469 u200d u1f467 by u1f468_u200d_u1f469_u200d_u1f467; // Father and Mother and Daughter
...
}碼位的轉換
因此,想要把一個 Emoji 轉換成對應的碼位以用於儲存,其實不能很單純的使用 codeAtPoint method 去轉換,而是要考慮各種分解的狀態:
- Emoji 的
.length必定大於2,需要代理對碼位的轉換。 - 對於
.length為奇數的,必定存在至少一個.length為 1 的 ZWJ 字符,碼位為U+200D。 .length大於2的 Emoji,是由複數個 Emoji 組成,在轉換時必須遵從 FIFO 原則,依序列出。
function emojiToUnicode(thisEmoji) {
var res = [];
const subEmojis = [...thisEmoji];
subEmojis.forEach((ele, _) => {
// 考慮 ZWJ 的存在
if (ele.length === 1) {
res.push(ele.charCodeAt(0).toString("16").toUpperCase());
}
// 考慮透過代理對表示的 Emoji
else if (ele.length === 2) {
const comp =
(ele.charCodeAt(0) - 0xd800) * 0x400 +
(ele.charCodeAt(1) - 0xdc00) +
0x10000;
res.push(comp.toString("16").toUpperCase());
}
});
// 按照順序印出,並加上 U+ 的前綴
return `U+${res.join("+")}`;
}
~emojiToUnicode("🍎") > "U+1F34E";
~emojiToUnicode("👩🚒") > "U+1F469+200D+1F692";
~emojiToUnicode("🇹🇼") > "U+1F1F9+1F1FC";
~emojiToUnicode("👨👩👧") > "U+1F468+200D+1F469+200D+1F467";轉回來則相對簡單,把剛剛得到的碼位一一排序輸出即可
function unicodeToEmoji(unicodes) {
var res = []
const codes = unicodes.replace('U+', '').split('+');
codes.forEach((code, _) => {
const intCodePoint = parseInt(code, 16);
const character = String.fromCodePoint(intCodePoint);
res.push(character)
})
// 將結果依序印出
return res.join('')
}
~ unicodeToEmoji('U+1F468+200D+1F469+200D+1F467')
> '👨👩👧'Emoji 的輸入方法
在各個主流作業系統裡,其實都已經內建了輸入 Emoji 的方式,例如在 Windows 裡,可以透過「windows + .」打開 Emoji 鍵盤、而在 macOS 裡,則可以透過「control + command + space」啟用;置於 Android 和 iOS 移動設備端,也會有 Emoji 小鍵盤可以輸入。
不過,想必還是會有使用者不知道這些快捷鍵,至今還是透過複製貼上的方式來輸入,因此,我們想要直接放置一個 Emoji 挑選器——直觀、簡單、又方便。
Emoji-Mart
如果在 Github 上搜尋 Emoji picker 之類的關鍵字,可以找到不少的 repo,在這裡,我們以 Star 數最多、更新最為頻繁的 emoji-mart 套件 為例。
emoji-mart 除了 Picker(選擇器)的本體之外,還需要額外掛載紀錄 emoji 的 data。除了遠端 fetch 回來的方法之外:
import { Picker } from 'emoji-mart'
new Picker({
data: async () => {
const response = await fetch(
'https://cdn.jsdelivr.net/npm/@emoji-mart/data',
)
return response.json()
}
})也可以直接把 data 的部分 bundle 起來:
import { Picker } from 'emoji-mart'
import data from '@emoji-mart/data'
new Picker({ data })Options
emoji-mart 的 repo 裡面有詳細紀錄建立一個 Picker 可以賦予的選項,其中最常設置的有以下幾個:
data:Emoji 的資料。如上一章所示,差別就在於要聯網從 remote 抓取回來、或是直接 bundle 打包起來。onEmojiSelect:選取 Emoji 時要觸發的動作。以今天的目標為例,就是要讓使用者在點選任一個 Emoji 時,可以傳回該 Emoji 的資料。emojiVersion:Emoji 的版本。這個版本號與 Unicode 的版本號一致,換句話說,目前最新的 Unicode 15.1 對應的就是 Emoji 15.1 版本。比較可惜的是,emoji-mart的版本目前停留在14.0,也就是 2021 年九月的版本。更新版本的 Emoji 如(請確定你裝置的字型也有更新才會正確顯示) 🫨(顫抖的臉U+1FAE8)、🫎(麋鹿U+1FACE)、🪿(鵝U+1FABF)、🪼(水母U+1FABC)就不在 Picker 裡面。set:要用哪套 Emoji。除了隨使用者裝置顯示的native之外,可選的還有apple、facebook、google以及twitter。

至於要選擇哪一種風格集嘛~這裡提到的四種 set 可以說是四分天下,apple 和 google 風格佔據了 iOS/macOS 和 Android 的市場份額,而 facebook 和 twitter 也是許多人日常一定會使用的社群網站。使用者對他們應該都相對熟悉,所以端看網頁需求即可。
onEmojiSelect
每當使用者點選任一個 Emoji 的時候,就可以藉由 onEmojiSelect 回傳該 Emoji 的詳細資訊,我們可以印出這個資訊的 Object 看看:
const pickerOptions = { onEmojiSelect: (res, _) => console.log(res) }在點選 🐬 之後,我們就可以得到 🐬 的資訊啦:
> {id: 'dolphin', name: 'Dolphin', native: '🐬', unified: '1f42c', keywords: Array(8), …}
aliases: ['flipper']
id: "dolphin"
keywords: (8) ['flipper', 'animal', 'nature', 'fish', 'sea', 'ocean', 'fins', 'beach']
name: "Dolphin"
native: "🐬"
shortcodes: ":dolphin:"
unified: "1f42c"裡面有一些有趣的東西,像是 Emoji 本體 native、名字 name、代表 Unicode 唯一碼位的 unified、可以找到該 Emoji 的關鍵字 keywords 等等。而我們真正需要的,可以是本體 native,也可以是代表碼位的 unified,畢竟兩者之間的關係是唯一的。
本文同步刊於 iThome。詳見DAY 20 | Emoji:可愛的小東西、DAY 24 | Emoji Mart:讓使用者挑喜歡的 Emoji。