[Tech] OpenType 標記語言:AFDKO
在上一篇文章裡,我們介紹了一些很常見的 feature,我們接下來看看如何在 OpenType 裡實現他們。
用來標記 feature 的「語言」其實並沒有統一的規定,如 Adobe 開發的 AFKDO(Adobe Font Development Kit for OpenType)、Microsoft 的 VOLT (Visual OpenType Layout Tool) 等等。
在這裡,我們會介紹最通用的 AFKDO 語言。
額外注意的是,AFKDO 僅僅是一種標記用的語言,跟 HTML 類似,他本身僅僅用來描述,並沒有辦法進行複雜的邏輯判斷。
取名原則
- 每個字符的名稱必須要小於 63 個字元。
- 只允許使用大小寫
A到Z、數字、英文句點(.)、以及底線(_)命名。 - 字元名稱不能以數字開頭。
- 通常來說,位處 BMP 上的字符(四位數)會以
uniXXXX開頭,而輔助平面上的(五位數的 Unicode)則為uXXXXX。 - 允許使用易讀的名稱命名字符。例如
$可以是uni0024,也可以是dollar;Ω可以是uni03A9,也可以是Omega;あ可以是uni3042,也可以是a-hira。- 通常來說,我們習慣使用
<parent>.<child>來表示同字母的父子關係,例如A.sc就是和A有關。 <alphabet>-<script>則用來表示同一種文字系統,例如「ㄅ(b-bopomofo)、ㄆ(p-bopomofo)」;「あ(a-hira)、さ(sa-hira)」;「Д(De-cy)、Ж(Zhe-cy)」,看得出來是同一家人。
- 通常來說,我們習慣使用
- 除了用來標示缺字(也就是豆腐)的
.notdef字符之外,字元名稱不能以,和-開頭。- 舉例來説,
a、Kappa、space、dollar、uni60C5、twodots、j.full、m_hungarumlautcomb都是可用的字符名稱 - 但
2dots、.uni597D、._.A則無法使用
- 舉例來説,
類別
- 隱式列舉:可以透過
[ ... ]的方式將數個字符名稱包在其中,用空格分開,使其視為同一類別- 例如:
space [endash emdash figuredash] space - 等價於
space endash space且space emdash space且space figuredash space
- 例如:
- 對於英文與數字、以及其字序列,可以透過
-字符取得一定的範圍- 語法:
[<firstGlyph> - <lastGlyph>] - 例如:
[A.swash - Z.swash]或[a - z]或[0 - 9]
- 語法:
- 顯式列舉
- 語法:
@<name> = [ ... ] - 例如:透過
@dash = [endash emdash figuredash];進行 assign - 使用時:
space @dash space
- 語法:
- 可使用巢狀結構
@Vowels.lc = [a e i o u];
@Vowels.uc = [A E I O U];
@Vowels = [@Vowels.lc @Vowels.uc];
## 等價於
@Vowels = [a e i o u A E I O U];基本特性編寫方式
feature <name> [useExtension] {
## rules...
} <name>;其中,<name> 為 feature 的名字。長度恆為四個字母,必須要和 OpenType 規格的定義相同,否則無法被軟體正確的讀取與啟用。當該區塊的規則超過 64 KB 時,可以透過 [useExtension] 語法拓展要寫入的規則。每行最後應該使用分號 ; 表示結尾。
例如以下是一個把 ff 處理成 f_f 連字的特性規則:
feature liga {
sub f f by f_f;
} liga;巢狀規則
feature <name> {
…
} <name>;等價於
feature <name> {
lookup <label> {
…
} <label>;
} <name>;這樣的好處,在於可以透過 label 更清楚標示我們要替換的規則,例如下方的 pnum 特性包裝了用於拉丁字母的 pnum_latin 跟阿拉伯字母的 pnum_arab:
feature pnum {
lookup pnum_latin {
sub zero by zero.prop;
sub one by one.prop;
sub two by two.prop;
...
} pnum_latin;
lookup pnum_arab {
sub uni0660 by uni0660.prop;
sub uni0661 by uni0661.prop;
sub uni0662 by uni0662.prop;
...
} pnum_arab;
} sups;甚至可以在不同的 feature 中引用同一組 lookup 規則,讓版面更好閱讀
lookup myAlternates {
sub A by A.001; ## Alternate form
...
} myAlternates;
feature salt { lookup myAlternates; } salt;
feature ss01 { lookup myAlternates; } ss01;替換方式
從前面介紹的連字、上下文替代、文體集與字符組成等等,不難發現他們背後的邏輯都是「替換」(lookup)。在 OpenType 裡總共定義了八種替換方式,如下表所示:
| Value | Type | 替換規則 |
|---|---|---|
| 1 | Single | 將一個字符換成另一個字符 |
| 2 | Multiple | 將一個字符換成多個字符 |
| 3 | Alternate | 將一個字符換成多個可能字符之一 |
| 4 | Ligature | 將多個字符換成另一個字符 |
| 5 | Context | 根據前後文替換多個字符 |
| 6 | Chaining Context | 根據串接的前後文替換多個字符 |
| 7 | Extension Substitution | 用於擴充 |
| 8 | Reverse chaining context single | 根據連續前後文反方向替換多個字符(通常用於阿拉伯文) |
對應前幾天我們所介紹的 feature 們:
| feature | 中文 | Lookup | 預設 |
|---|---|---|---|
| liga | 標準連字 | 4 | 預設開啟,但可關閉的連字 |
| dlig | 可擇連字 | 4 | 預設不開啟 |
| hlig | 歷史連字 | 4 | 預設不開啟 |
| smcp | 小寫轉小型大寫字母 | 1 | 預設不開啟 |
| c2sc | 大寫轉小型大寫字母 | 1 | 預設不開啟 |
| swsh | 花飾字 | 1 | 預設不開啟 |
| salt | 預設文體替代字 | 1 | 預設不開啟,通常建議等於 ss01 |
| ss01-ss20 | 文體集 | 1 | 預設不開啟 |
| calt | 上下文替代字 | 6 | 預設開啟 |
| vert | 豎排 | 1 | 預設開啟 |
| vrt2 | 豎排・改 | 1 | 預設開啟 |
| ccmp | 字符分解與組合 | 4, 2 | 強制套用 |
LookupType 1: Single substitution
白話來說就是一換一,把一個字符換成另一個字符是 OpenType 裡面最常見的替換方式。在 AFKDO 裡,主要有三種寫法:
substitute <glyph> by <glyph>; ## format A
substitute <glyphclass> by <glyphclass>; ## format B其中,substitute 標記可以簡寫為 sub,也請不要忘記在最後面加上分號。
舉例來說,我們想設計一套可以使用 smcp 特性的字型,所以在基本型之外,我們還額外設計了 A.sc - Z.sc 的小寫轉小型大寫字母,這裡的 sc 指的是 small caps,透過 . 串接,可以讓我們更清楚知道 A.sc 是 A 的子集。
我們可以使用 format A 的格式來窮舉一組 smcp 特性:
feature smcp {
substitute a by A.sc;
substitute b by B.sc;
substitute c by C.sc;
... 中略 D ~ Y
substitute z by Z.sc;
} smcp;直譯而言,就是在啟用 smcp 特性時,將小寫的 a 到 z 轉成 A.sc 到 Z.sc。
或是透過昨天介紹的範圍列舉 [ <start> - <end> ] 的 format B,簡單的寫成:
feature smcp {
substitute [a - z] by [A.sc - Z.sc];
} smcp;或是額外設定兩組 class,這樣的好處是在其他地方可以重複調用 @Lowers 和 @SmallCaps:
@Lowers = [a - z];
@SmallCaps = [A.sc - Z.sc];
feature smcp {
substitute @Lowers by @SmallCaps;
} smcp;三者的表達方式都是等價的。
有興趣的可以類推前幾天提到的 smcp, c2cp, swsh, salt, ss##,其實都是額外設計一格字符,再把原本的轉成我們指定要的。
LookupType 2: Multiple substitution
白話來說就是一換多,不過對我們熟悉的文字來說都蠻少會用的,基礎語法為:
substitute <glyph> by <glyph sequence>;以 liga 來說,假設我們想讓使用者反向解開設定好的連字,便可以使用:
substitute f_f_i by f f i;或是把 & 這個符號,還原成原本的 Et:
substitute ampersand to E t;LookupType 3: Alternate substitution
其實也是…蠻少用的,通常用於 trad feature 這種,可以讓使用者在輸入簡體字或日文新字型後,從多個字符裡面手動選擇繁體字或是舊字型。
基礎語法為:
substitute <glyph> from <glyphclass>;LookupType 4: Ligature substitution
多換一,也就是將多個字符轉換成一個字符也是相當常用的一種方式,基本用於處理連字,語法為
substitute <glyph sequence> by <glyph>;以標準連字功能而言,我們可以定義一系列和 f 有關的字符對,讓使用者在輸入他們的時候,將輸入的字符轉成對應的連字,
feature liga {
sub f f by f_f;
sub f i by f_i;
} liga;要特別注意的是,AFDKO 和多數的語言一樣,會由上往下執行替換規則。雖然規格上 AFDKO 有要求軟體處理 理想 的連字排序,但實際上多數的軟體不會自動排列順序,所以在編寫規則的時候,必須考慮指定執行的順序。
以下面的規則來說,我們必須要優先處理 ffi 轉 f_f_i 的連字,所以 ffi 規則要寫在最上面。
## 正確的順序
feature liga {
sub f f i by f_f_i;
sub f f by f_f;
sub f i by f_i;
} liga;反之,如果順序寫反了,把 ffi 置於最後,則軟體在執行第一條規則時, ffi 就會優先被轉成 [f_f]i,接下來的規則就無法觸發了。
## 錯誤的順序
feature liga {
sub f f by f_f;
sub f i by f_i;
sub f f i by f_f_i;
} liga;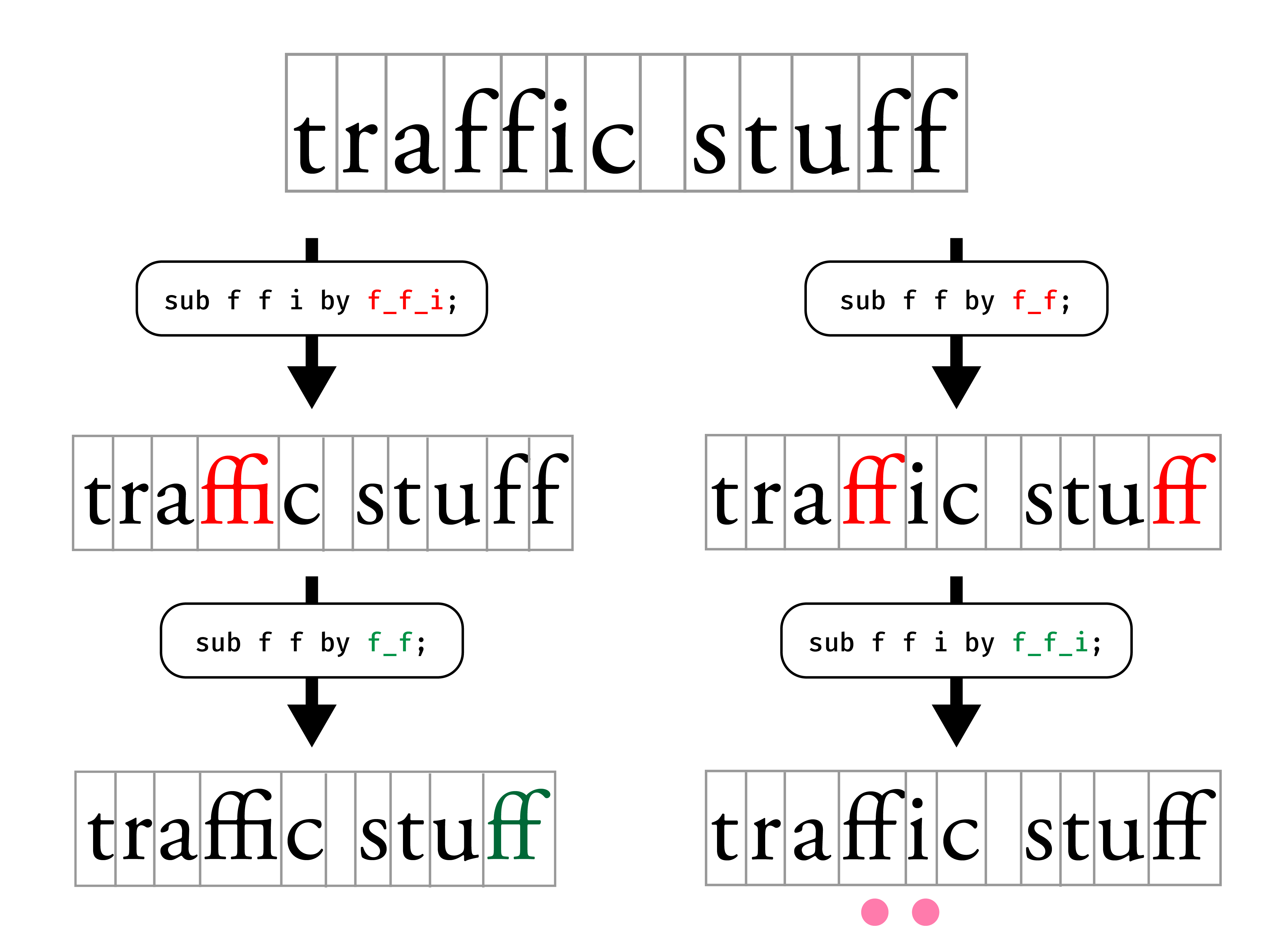
除了連字系列的 feature 之外,另一個例子是 frac 特性,可以將數字、slash(/)、數字,合併成一個分數的樣子
feature frac {
substitute [one one.oldstyle] [slash fraction] [two two.oldstyle] by onehalf;
...
} frac;在這裡,我們使用方括號進行枚舉,因此,上面的規則等價於下面的表達式
feature frac {
substitute one slash two by onehalf;
substitute one.oldstyle slash two by onehalf;
substitute one fraction two by onehalf;
substitute one.oldstyle fraction two by onehalf;
substitute one slash two.oldstyle by onehalf;
substitute one.oldstyle slash two.oldstyle by onehalf;
substitute one fraction two.oldstyle by onehalf;
substitute one.oldstyle fraction two.oldstyle by onehalf;
} frac;用於歐文連字之外
連字的設計對歐文來說或許非必要(沒有 f_i 這類的還是看得懂,只是很醜而已),但對於許多文字的表示至關重要,尤其是婆羅米系文字,常常會出現複子音或是母音變形的現象。
以柬埔寨語使用的高棉文(Khmer)為例,當一個詞出現兩個以上的子音的時候,第二個之後的子音需要被「折疊」到第一個子音之下。
在柬埔寨的國名 កម្ពុជា [k-mpou-chea] 裡,第二個字母便出現了 [mp-] 這樣的雙子音。此時對輸入法而言,兩個子音之間透過子音附加符(U+17D2)連接在一起,會將後面的 [p-] 子音「折疊」到第一個 [m-] 子音之下,折疊的 [p-] 子音會以附加型(subscript form)出現。
而在高棉文的 ខ្មែរ [Khmer] 裡,此時的 [m-] 子音為第二子音,在輸入時會位於子音附加符之後,所以會被折疊到 [k-] 子音的下面,並以附加型表示。
相較於母音可以使用附加符號的去組合(類似 ccmp),附加型的子音會變形,因此可以透過連字的判斷,當「子音附加符」與子音出現時,便將後面的子音轉成附加型。
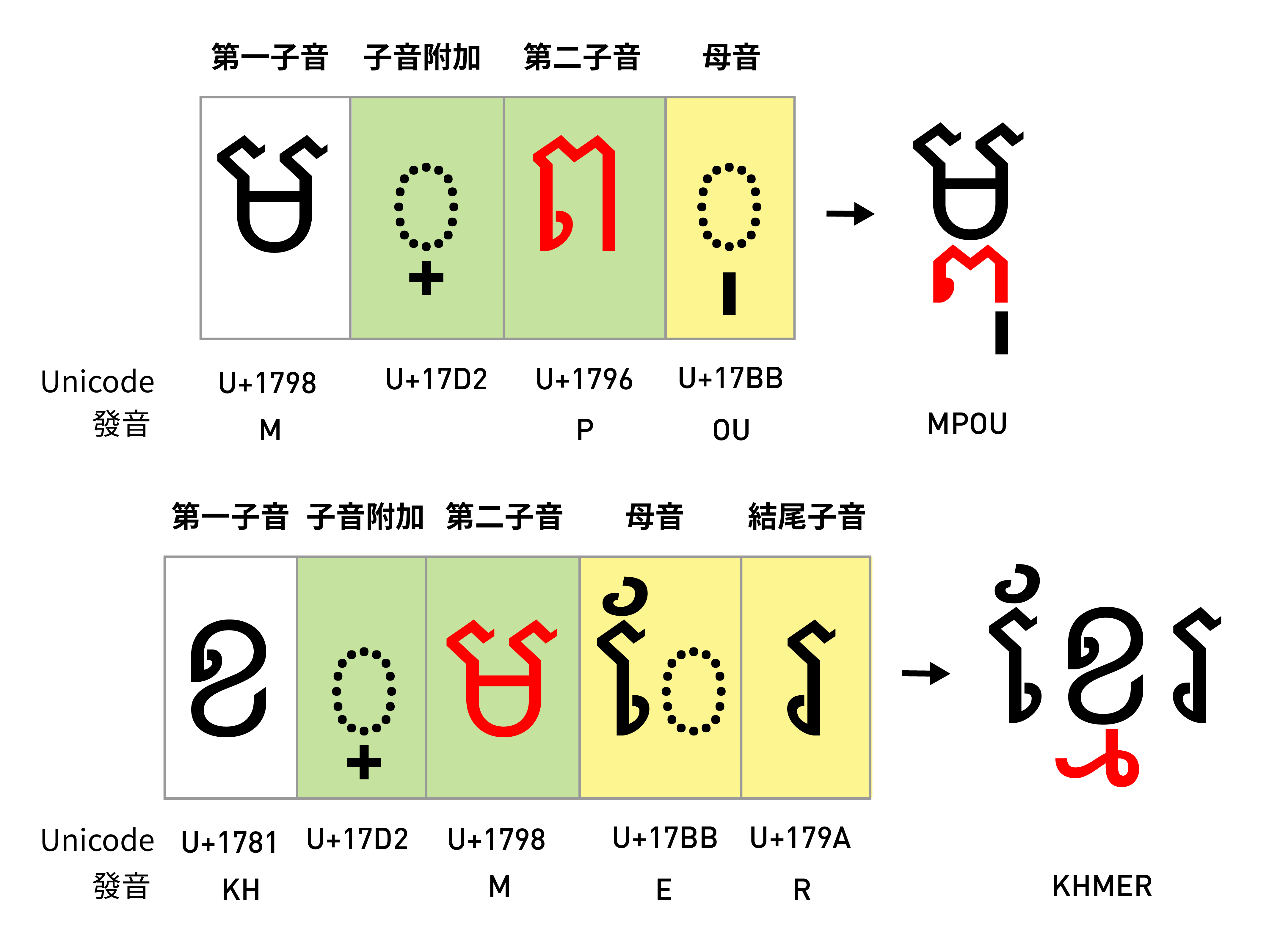
feature blwf {
sub uni17D2 uni1796 by uni1796.below; ## p-
sub uni17D2 uni1798 by uni1798.below; ## m-
...
} blwf;在婆羅米系的文字裡,很常會看到樣貌完全不同的附加型。其並不是直接使用歐文的 ccmp 和 liga,OpenType 裡面有更複雜的 pref(置前形式)、blwf(置下形式)、abvf(置上形式)、pstf(置後形式)、pres(置前替代形式)、blws(置下替代形式)、abvs(置上替代形式)、psts(置後替代形式)等 feature 可以操作,但原理其實都是 LookupType 4: Ligature substitution 的替換,和 ccmp 與 liga 的邏輯是一樣的。
LookupType 6: Contextual substitution
由於 LookupType 5 算是 LookupType 6 的子集功能,因此這裡一起講解。Contextual substitution 可以說是最複雜的替換類別。
對於像是 calt 這類只在符合特定前後文時進行取代的 feature,我們必須枚舉所有的可能性,並在要「被取代」的字符後方加上 ' 符號,讓 OpenType 知道該字符是要被替換的對象。舉例來説,以上次我們提到的 gj 字符對,便需要枚舉,並且指定後面的 j 進行替換:

feature calt {
sub g j' by j.alt; ## 出現 gj 時,將後面 j 顯示成 j.alt 字符
} clat;而被取代的字也可以不只一個,例如將 etc 替換成 &c:
feature calt {
sub e' t' c by ampersand; ## etc 連續出現時,將 et 取代成 ampersand 字符
} calt;Ignore 例外處理
上下文取代的語法可以組合成相當複雜的樣子,還可以配合 ignore ,針對某些特例的上下文,選擇性的忽視某些通則。
以上次提到的將錯字「尋(uni5C0B)問(uni554F)」轉成「詢(uni8A62)問」來說,我們先寫出規則,指定當「尋問」二字連續出現時,將前面的 尋 替換成 詢,但同時,我們又必須避開「千尋問鍋爐爺爺…」這樣的規則,因此我們再次枚舉出「千(uni5343)尋(uni5C0B)問(uni554F)」這樣的省略規則:
feature calt {
ignore substitute uni5343 uni5C0B' uni554F;
substitute uni5C0B' uni554F by uni8A62;
} calt;如此一來,尋問 二字就會替換成 詢問,但如果前面出現 千 字時,feature 就會省略掉這串字符,讓文字保持著原本的樣子。
LookupType 7 擴充
當使用的規則可能會超過 64K 時,可以加上 useExtension 字樣進行擴充。
feature aalt useExtension {
feature salt;
feature smcp;
substitute d by d.alt;
## ... other rules
} aalt;LookupType 8 反向前後文連鎖
將原本的 substitute (sub) 指令改用 reversesub 或 rsub,其他的觀念都和 LookupType 6 相通。
對排版渲染引擎來說,會從一個詞的最後方開始往前比對。通常用於處理阿拉伯文的 init、medi、fina、isol 特性——同一個字在一個詞的不同位置,會有不同的樣子,置於詞首、詞中、詞尾、或是單獨存在時都長得不一樣,這部分是漢字文化圈的我們比較難以想像的。
本文同步刊於 iThome。詳見DAY 14 | OpenType 標記語言:AFDKO、DAY 15 | AFKDO (1):LookupType 1 ~ 3、DAY 16 | AFKDO (2):LookupType 4、DAY 17 | AFKDO (3):LookupType 5~8。